实现测试框架前的准备
初识:Google 测试框架
Google 开发的单元测试框架 Google Test,我们一般称它为 gtest。
测试代码
1 |
|
测试输出
1 | [==========] Running 2 tests from 1 test suite. |
先看输出内容的第 4 行和第 6 行,意思是说,执行测试用例 test_is_prime.test1 和 test_is_prime.test2,这不就是上面两个以 TEST 开头的两段代码相关的输出内容么?
接下来从第 7 行到第 21 行是一段报错信息,意思就是说 is_prime(4),is_prime(0) 与 is_prime(1) 函数返回值错误,也就意味着 is_prime 函数实现有错误,这段错误所涉及的信息,在源代码中的第二个测试用例中有涉及。
对于 gtest 的三个思考
面对刚才的演示代码和输出内容,你可能会产生如下三个问题:
- 1,代码中的 EXPECT_EQ 是做什么的?
- 2,以 TEST 开头的代码段,和我们学习的函数很不一样,那它究竟是什么?
- 3,主函数中只调用了 RUN_ALL_TESTS 函数,为什么好像是执行了程序中所有的 TEST 代码段?这个功能是怎么实现的?
第一个问题不难,查看相关 gtest 的文档资料,你就可以知道,EXPECT_EQ 是 gtest 里面自带的宏,主要作用是判断传入的两部分的值是否相等。如果不相等,就会产生类似于输出内容中第 7 行到第 21 行的输出内容。
第二个问题,以 TEST 开头的这段代码,明显不符合我们对 C 语言的语法认知,我们确实没有见过不用规定返回值类型,也不用规定参数类型的函数定义方式。关于 TEST 究竟是个什么的问题,更加合理的猜测,就是 TEST 实际上是一个宏。
宏的作用,是做简单的替换。正是因为 TEST(test_is_prime, test1) 这段代码实际上是一个宏,所以展开以后,和后面的大括号中的内容一起组成了一段合法的代码内容。
小结
- 测试行为,不是测试工程师的专属,你应该把它作为一个开发工程师的习惯。
- 单元测试属于白盒测试范畴,Google 的 gtest 就是一种辅助我们编写单元测试的框架。
- gtest 中的 TEST 本质上是一个宏,而这个宏应该展开成怎样的代码内容,还需要你认真思考,这个思考过程对你来说是很有价值的。
实现一个自己的测试框架
初步实现 TEST 宏
我们实现的所有代码,都会写在一个名字为 geek_test.h的头文件中。(注意:将声明和定义写在一起,在大型工程中是会出现严重的编译错误,在实际的工程开发中,我们并不会这么做。)
我们的目的,是在不改变这份源代码的前提下,通过在 geek_test.h 中添加一些源码,使得这份代码的运行效果,能够类似于 gtest 的运行效果。
想要完成这个目标,我们就要先来思考 TEST 宏这里的内容,请你仔细观察这段由 TEST 宏定义的测试用例的相关代码:
1 | TEST(test1, test_is_prime) { |
TEST(test1, test_is_prime) 这部分应该是在调用 TEST 宏,而这部分被预处理器展开以后的内容,只有和后面大括号里的代码组合在一起,才是一段合法的 C 语言代码,也只有这样,这份代码才能通过编译。既然如此,我们就不难想到,TEST 宏展开以后,它应该是一个函数定义的头部,后面大括号里的代码,就是这个展开以后的函数头部的函数体部分,这样一切就都说得通了。
在实现 TEST 宏之前,我们还需要想清楚一个问题:由于程序中可以定义多个 TEST 测试用例,如果每一个 TEST 宏展开都是一个函数头部的话,那这个展开的函数的名字是什么呢?如果每一个 TEST 宏展开的函数名字都一样,那程序一定无法通过编译,编译器会报与函数名重复相关的错误,所以, TEST 宏是如何确定展开函数的名字呢?
注意,TEST 宏需要传入两个参数,这两个参数在输出信息中与测试用例的名字有关。那我们就该想到,可以使用这两个参数拼接出一个函数名,只要 TEST 传入的这两个参数不一样,那扩展出来的函数名就不同。最后,我们就可以初步得到如下的 TEST 宏的一个实现:
1 |
如代码所示的 TEST 宏实现,我们将 TEST 宏的两个参数内容使用 ## 连接在一起,中间用一个额外的下划线连接,组成一个函数名字,这个函数的返回值类型是 void,无传入参数。根据这个实现,预处理器会将源代码中两处 TEST 宏的内容,替换成如下代码所示内容:
1 | void test1_test_is_prime() { |
__attribute__:让其它函数先于主函数执行
先,我们先来看如下代码:
1 |
|
代码运行以后,会输出一行字符串 “hello main!”。
接下来呢,我们对上述代码稍微修改,在 pre_output 函数前面加上__attribute__((constructor)) 。这样,pre_output 函数就会先于主函数执行,代码如下:
1 |
|
如上代码执行以后,程序会输出两行内容,第 1 行是 pre_output 函数输出的内容 “hello geek!”,第 2 行才是主函数的执行输出内容 “hello main!”。
从输出内容可以看出,加了__attribute__((constructor)) 以后,pre_output 函数会先于 main 主函数执行。
RUN_ALL_TESTS 函数设计
从主函数中调用 RUN_ALL_TESTS 函数的方式来看,RUN_ALL_TESTS 函数应该是一个返回值为整型的函数。这样,我们可以得到这样的函数声明形式:
1 | int RUN_ALL_TESTS(); |
从测试框架的执行输出结果中看,RUN_ALL_TESTS 函数可以依次性地执行每一个 TEST 宏扩展出来的测试用例函数,这是怎么做到的呢?
我们可以这样认为:在主函数执行 RUN_ALL_TESTS 函数之前,有一些函数过程,就已经把测试用例函数的相关信息,记录在了一个 RUN_ALL_TESTS 函数可以访问到的地方,等到 RUN_ALL_TESTS 函数执行的时候,就可以根据这些记录的信息,依次性地执行这些测试用例函数。整个过程,如下图所示:
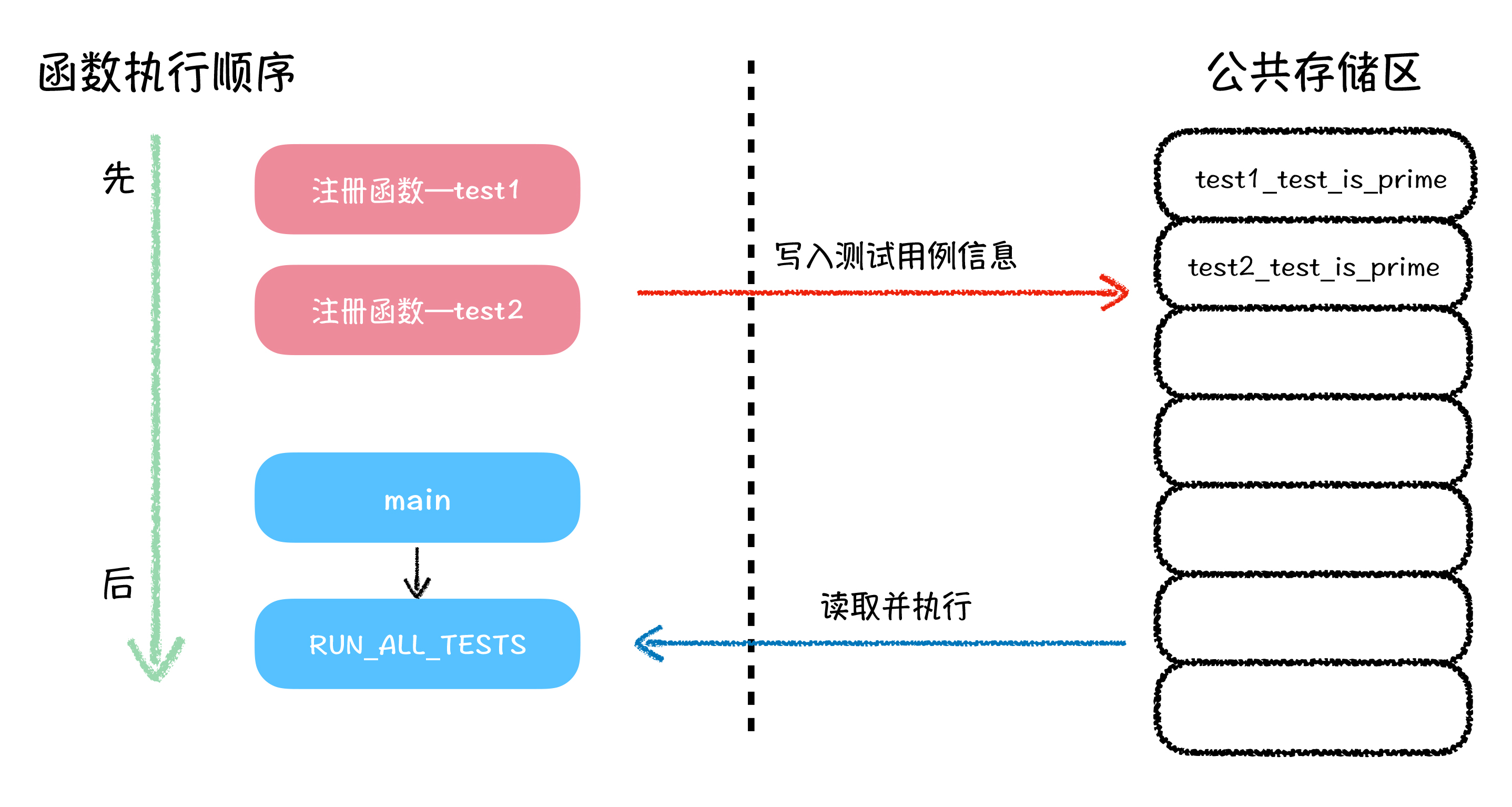
图中红色部分,就是我们推测的,某些完成测试用例函数信息注册的函数,它们先于主函数执行,将测试用例的信息,写入到一个公共存储区中。
接下来,我们需要考虑的就是这些注册函数,究竟将什么信息存储到了公共存储区中,才能使得 RUN_ALL_TESTS 函数可以调用到这些测试用例?你自己也可以想想是什么。答案就是这个信息是测试用例函数的函数地址,因为只有把函数地址存储到这个存储区中,才能保证 RUN_ALL_TESTS 函数可以调用它们。所以,这片公共存储区,就应该是一个函数指针数组。
那如何解决注册函数问题呢?最简单直接的设计方法,就是每多一个由 TEST 宏定义的测试用例,就配套一个注册函数,所以这个注册函数的逻辑,可以设计在 TEST 宏展开的内容中。这就需要我们对 TEST 宏进行重新设计。
我们先来完成 RUN_ALL_TESTS 函数从存储区中,读取并执行测试用例的过程:
1 | typedef void (*test_function_t)(); |
代码中用到了函数指针相关的技巧,其中 test_function_t 是我们定义的函数指针类型,这种函数指针类型的变量,可以用来指向返回值是 void,传入参数为空的函数。
之后,定义了一个有 100 位的函数指针数组 test_function_arr,数组中的每个位置,都可以存储一个函数地址,数组中元素数量,记录在整型变量 test_function_cnt 中。这样,RUN_ALL_TESTS 函数中的逻辑就很简单了,就是依次遍历函数指针数组中的每个函数,然后依次执行这些函数,这些函数每一个都是一个测试用例。
重新设计:TEST 宏
根据前面的分析,TEST 扩展出来的内容,不仅要有测试用例的函数头部,还需要有先于主函数执行的注册函数,主要用于注册 TEST 扩展出来的测试用例函数。由此,我们可以得出如下示例代码:
1 |
这个新设计的 TEST 宏,除了末尾保留了原 TEST 宏内容以外,在扩展的测试用例函数头部添加了一段扩展内容,这段新添加的扩展内容,会扩展出来一个函数声明,以及一个以 register 开头的会在主函数执行之前执行的注册函数;注册函数内部的逻辑很简单,就是将测试函数的函数地址,存储在函数指针数组 test_function_arr 中,这部分区域中的数据,后续会被 RUN_ALL_TESTS 函数使用。
如果以如上 TEST 宏作为实现,原程序中的两个测试用例代码,会被展开成如下样子:
1 | void test1_test_is_prime(); |
至此,我们就算是初步完成了测试框架中关键的两个部分的设计:一个是 TEST 宏,另外一个就是 RUN_ALL_TESTS 函数。它们同时也是串起测试框架流程最重要的两部分。
小结
- attribute((constructor)) 可以修饰函数,使修饰的函数先于主函数执行。
- RUN_ALL_TESTS 之所以可以获得程序中所有测试用例的函数信息,是因为有一批注册函数,将测试用例函数记录下来了。
- 通过测试框架这个项目,我们再一次看到,宏可以将原本看似不合理的代码,变得合理。

