介绍
Nebula Graph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
图数据库是专门存储庞大的图形网络并从中检索信息的数据库。它可以将图中的数据高效存储为点(Vertex)和边(Edge),还可以将属性(Property)附加到点和边上。
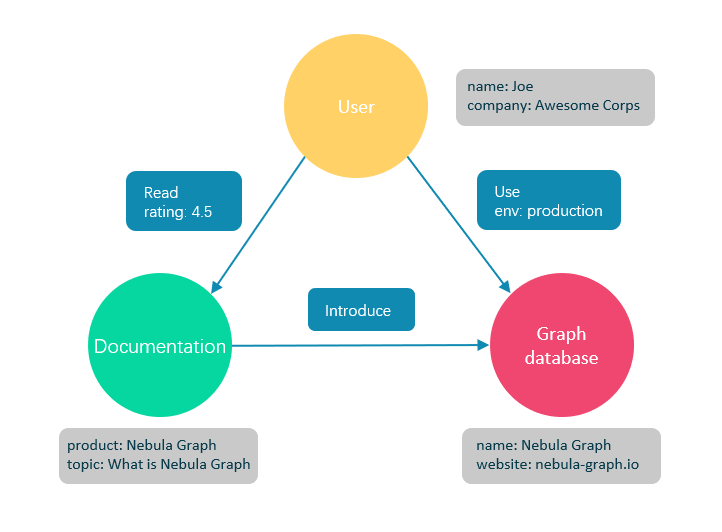
图数据库概念
数据模型
图空间(Space):用于隔离不同团队或者项目的数据。不同图空间的数据是相互隔离的,可以指定不同的存储副本数、权限、分片等。
点(Vertex):来保存实体对象,特点是点是用点标识符(VID)标识的。VID在同一图空间中唯一。VID 是一个 int64,或者 fixed_string(N);点必须有至少一个 Tag,也可以有多个 Tag。但不能没有 Tag。
边(Edge):用来连接点的,表示两个点之间的关系或行为,特点如下
两点之间可以有多条边。
边是有方向的,不存在无向边。
四元组 <起点 VID、Edge type、边排序值 (Rank)、终点 VID> 用于唯一标识一条边。边没有 EID。
一条边有且仅有一个 Edge type。
一条边有且仅有一个 rank。其为 int64,默认为 0。标签(Tag):Tag 由一组事先预定义的属性构成。
边类型(Edge type):Edge type 由一组事先预定义的属性构成。
属性(Properties):属性是指以键值对(Key-value pair)形式存储的信息。
路径
路径是指一个有限或无限的边序列,这些边连接着一系列点。
walk
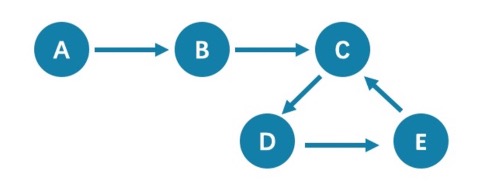
walk类型的路径由有限或无限的边序列构成。遍历时点和边可以重复。
查看示例图,由于 C、D、E 构成了一个环,因此该图包含无限个路径,例如A->B->C->D->E、A->B->C->D->E->C、A->B->C->D->E->C->D。
注:GO语句采用的是walk类型路径。
trail
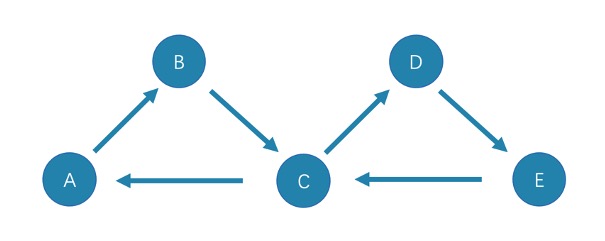
trail类型的路径由有限的边序列构成。遍历时只有点可以重复,边不可以重复。柯尼斯堡七桥问题的路径类型就是trail。
查看示例图,由于边不可以重复,所以该图包含有限个路径,最长路径由 5 条边组成:A->B->C->D->E->C。
注:MATCH、FIND PATH和GET SUBGRAPH语句采用的是trail类型路径。
在 trail 类型中,还有cycle和circuit两种特殊的路径类型
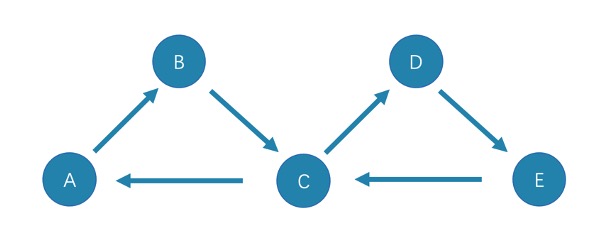
cycle
是封闭的 trail 类型的路径,遍历时边不可以重复,起点和终点重复,并且没有其他点重复。在此示例图中,最长路径由三条边组成:A->B->C->A或C->D->E->Ccircuit
是封闭的 trail 类型的路径,遍历时边不可以重复,除起点和终点重复外,可能存在其他点重复。在此示例图中,最长路径为:A->B->C->D->E->C->A。
path
path类型的路径由有限的边序列构成。遍历时点和边都不可以重复。
查看示例图,由于点和边都不可以重复,所以该图包含有限个路径,最长路径由 4 条边组成:A->B->C->D->E。
点 VID
在 Nebula Graph 中,一个点由点的 ID 唯一标识,即 VID 或 Vertex ID。
VID 的特点
- VID 数据类型只可以为定长字符串FIXED_STRING(
)或INT64;一个图空间只能选用其中一种 VID 类型。 - VID 在一个图空间中必须唯一,其作用类似于关系型数据库中的主键(索引+唯一约束)。但不同图空间中的 VID 是完全独立无关的。
- 点 VID 的生成方式必须由用户自行指定,系统不提供自增 ID 或者 UUID。
- VID 相同的点,会被认为是同一个点。
- VID 通常会被(LSM-tree 方式)索引并缓存在内存中,因此直接访问 VID 的性能最高。
VID 使用建议
- ebula Graph 1.x 只支持 VID 类型为INT64,2.x 支持INT64和FIXED_STRING(
)。在CREATE SPACE中通过参数vid_type可以指定 VID 类型。 - 可以使用id()函数,指定或引用该点的 VID;
- 可以使用LOOKUP或者MATCH语句,来通过属性索引查找对应的 VID;
- 性能上,直接通过 VID 找到点的语句性能最高,例如DELETE xxx WHERE id(xxx) == “player100”,或者GO FROM “player100”等语句。通过属性先查找 VID,再进行图操作的性能会变差,例如LOOKUP | GO FROM $-.ids等语句,相比前者多了一次内存或硬盘的随机读(LOOKUP)以及一次序列化(|)。
VID 生成建议
- (最优)通过有唯一性的主键或者属性来直接作为 VID;属性访问依赖于 VID;
- 通过有唯一性的属性组合来生成 VID,属性访问依赖于属性索引。
- 通过 snowflake 等算法生成 VID,属性访问依赖于属性索引;
- 如果个别记录的主键特别长,但绝大多数记录的主键都很短的情况,不要将FIXED_STRING(
)的N设置成超大,这会浪费大量内存和硬盘,也会降低性能。此时可通过 BASE64,MD5,hash 编码加拼接的方式来生成。 - 如果用 hash 方式生成 int64 VID:在有 10 亿个点的情况下,发生 hash 冲突的概率大约是 1/10。边的数量与碰撞的概率无关。
定义和修改 VID 的数据类型
VID 的数据类型必须在创建图空间时定义,且一旦定义无法修改。
快速入门
安装,启动,连接可参考官方文档
使用常用 nGQL(CRUD 命令)
连接成功
1 | $ nebula-console -addr 127.0.0.1 -port 9669 -u root -p 123456 |
图空间和 Schema
一个 Nebula Graph 实例由一个或多个图空间组成。每个图空间都是物理隔离的,用户可以在同一个实例中使用不同的图空间存储不同的数据集。

为了在图空间中插入数据,需要为图数据库定义一个 Schema。Nebula Graph 的 Schema 是由如下几部分组成。
| 组成部分 | 说明 |
|---|---|
| 点(Vertex) | 表示现实世界中的实体。一个点可以有一个或多个标签。 |
| 标签(Tag) | 点的类型,定义了一组描述点类型的属性。 |
| 边(Edge) | 表示两个点之间有方向的关系。 |
| 边类型(Edge type) | 边的类型,定义了一组描述边的类型的属性。 |
检查 Nebula Graph 集群的机器状态
1 | (root@nebula) [(none)]> SHOW HOSTS; |
创建和选择图空间
执行如下语句创建名为basketballplayer的图空间。
1
nebula> CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30));
执行命令SHOW HOSTS检查分片的分布情况,确保平衡分布。
选择图空间basketballplayer
1
2
3
4
5
6(root@nebula) [(none)]> USE basketballplayer;
Execution succeeded (time spent 892/1250 us)
Sun, 23 Jan 2022 21:19:42 CST
(root@nebula) [basketballplayer]>
创建 Tag 和 Edge type
1 | nebula> CREATE TAG player(name string, age int); |
插入点和边
- 插入代表球员和球队的点。
1 | nebula> INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42); |
- 插入代表球员和球队之间关系的边。
1 | nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95); |
查询数据
- 从 VID 为player101的球员开始,沿着边follow找到连接的球员。
1 | (root@nebula) [basketballplayer]> GO FROM "player101" OVER follow; |
- 从 VID 为player101的球员开始,沿着边follow查找年龄大于或等于 35 岁的球员,并返回他们的姓名和年龄,同时重命名对应的列。
1 | (root@nebula) [basketballplayer]> GO FROM "player101" OVER follow WHERE $$.player.age >= 35 \ |
- 从 VID 为player101的球员开始,沿着边follow查找连接的球员,然后检索这些球员的球队。为了合并这两个查询请求,可以使用管道符或临时变量。
使用管道符
1 | (root@nebula) [basketballplayer]> GO FROM "player101" OVER follow YIELD dst(edge) AS id | \ |
使用临时变量
当复合语句作为一个整体提交给服务器时,其中的临时变量会在语句结束时被释放。
1 | (root@nebula) [basketballplayer]> $var = GO FROM "player101" OVER follow YIELD dst(edge) AS id; \ |
- FETCH语句示例
查询 VID 为player100的球员的属性。
1 | (root@nebula) [basketballplayer]> FETCH PROP ON player "player100"; |
修改点和边
用户可以使用UPDATE语句或UPSERT语句修改现有数据。
UPSERT是UPDATE和INSERT的结合体。当使用UPSERT更新一个点或边,如果它不存在,数据库会自动插入一个新的点或边。
注:每个 partition 内部,UPSERT 操作是一个串行操作,所以执行速度比执行 INSERT 或 UPDATE 慢很多。其仅在多个 partition 之间有并发。
- 用UPDATE修改 VID 为player100的球员的name属性,然后用FETCH语句检查结果。
1 | (root@nebula) [basketballplayer]> UPDATE VERTEX "player100" SET player.name = "Tim"; |
- 用UPDATE修改某条边的degree属性,然后用FETCH检查结果。
1 | (root@nebula) [basketballplayer]> UPDATE EDGE "player101" -> "player100" OF follow SET degree = 96; |
- 用INSERT插入一个 VID 为player111的点,然后用UPSERT更新它。
1 | (root@nebula) [basketballplayer]> INSERT VERTEX player(name,age) values "player111":("David West", 38); |
删除点和边
- 删除点
1 | (root@nebula) [basketballplayer]> DELETE VERTEX "player111", "team203"; |
- 删除边
1 | (root@nebula) [basketballplayer]> DELETE EDGE follow "player101" -> "team204"; |
索引
用户可以通过 CREATE INDEX 语句为 Tag 和 Edge type 增加索引。
- 为 name 属性创建索引 player_index_1。
1 | (root@nebula) [basketballplayer]> CREATE TAG INDEX player_index_1 ON player(name(20)); |
- 重建索引确保能对已存在数据生效。
1 | (root@nebula) [basketballplayer]> REBUILD TAG INDEX player_index_1 |
- 使用 LOOKUP 语句检索点的属性。
1 | (root@nebula) [basketballplayer]> LOOKUP ON player WHERE player.name == "Tony Parker" \ |
- 使用 MATCH 语句检索点的属性。
1 | (root@nebula) [basketballplayer]> MATCH (v:player{name:"Tony Parker"}) RETURN v; |
小结
以上就是Nebula Graph数据库的常用操作,后续我会再根据研究方向做深入的研究。

