SRE方法论
确保长期关注研发工作
所有的产品事故都应该有总结,无论有没有触发报警。
在保障服务SLO的前提下最大化迭代速度
错误预算,发布策略。
监控系统
alert、ticket、logging。
应急事件处理
- MTTF + MTTR
- 预案 playbook 最佳方法
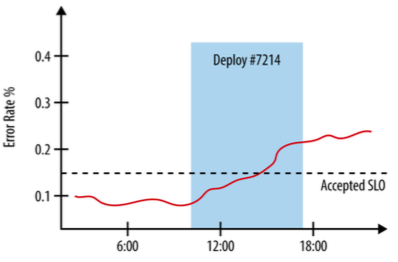
变更管理:70%的生产事故来自变更而触发
- 采用渐进式的发布机制
- 迅速而准确地检测到问题的发生
- 当发现问题时,安全迅速地回退变动
需求预测和容量规划:自然增长 + 非自然增长
- 必须有一个准确的自然增长需求预测模型,需求预测的时间应该超过资源获取的时间
- 规划中必须有准备的非自然增长需求来源的统计
- 必须有周期性的压力测试,以便准备地将系统原始资源与业务容量对应起来
资源部署
变更管理与容量规划的结合物。
效率与性能
- 持续的优化资源利用率,有效地降低系统的总成本
- 根据一个预设的延迟目标部署和维护足够的容量
我是一名软件工程师,这是我如何来应付重复劳动的办法。
Oncall
面向终端用户的服务,时间为5分钟。而非敏感的业务通常来说是30分钟
多个渠道可以收到报警(不限于邮件、短信、自动电话呼叫)
响应时间和业务的可靠性有关,如果服务为99.99%,那么每个季度有13分钟的不可用时间,所以oncall工程师要分钟级响应生产事故
一旦收到报警信息,工程师必须确认(ack),要能够及时定位问题并且尝试解决问题,必要的话要升级(escalate)请求支援
一般主oncall人值班,副oncall作为辅助,通常团队也可以彼此作为副oncall,互相值班,共同分担工作压力
oncall值班过程中,轮值工程师必须有足够的时间处理紧急事件和后续跟进工作,例如写事故报告
在面临挑战时,一个人会主动或者非主动选择下联方式处理:
- 依赖直觉,自动化、快速行动
- 理性、专注、有意识的进行认知类活动
当处理负载系统问题时,第二种行事方式是更好的,可能产生更好的处理结果,以及计划更周全的执行过程
凭直觉操作和快速响应看起来都是很有用的方法,但是这些方法都有自己的缺点。在有足够数据支撑的时候按步骤解决问题,同时不停地审核和验证目前所有的假设
Oncall可以寻求外部帮助
- 清晰的问题升级路线
- 清晰定义应急事件处理步骤
- 无指责,对事不对人的文化氛围
系统太稳定,容易松懈,定期轮值以及进行灾难恢复演习
有效的故障排查手段
通用的故障排查过程 + 发生故障的系统足够了解
排查过程反复采用“假设- 排除”
收到报警时,先搞清问题的严重程度
- 对于大型问题,立即声明一个全员参与的会议
- 大不多数的人第一反应是立即开始故障排除过程,试图尽快找到问题根源,正确做法是:尽最大可能让系统恢复服务,止损
- 快速定位问题时:保存问题现场,比如日志、监控等
监控系统记录了整个系统的监控指标,良好的Dashboard可以方便快速定位问题,比如Moni
日志是另外一个无价之宝,日志记录每个操作的信息和对应的系统状态可以让你了解在某一个时刻整个组件究竟在做什么,比如Billions
链路追踪工具,比如Dapper
Debug客户端,以便了解这个组件在收到请求后具体返回了什么信息
最后一个修改:一个正常工作的系统,直到某种外力因素出现。
一个配置文件修改,用户流量的改变,检查最近对系统的修改可能对查找问题根源很有帮助。
紧急事件响应
不要慌,你不是一个人在战斗!
如果你感到自己难以应付,就去找更多人参与
通知公司内的其他部门目前情况
经常性的进行灾难处理和应急响应演习
大型测试中一定先测试回滚机制
应急响应要让其他人得到清晰和及时的事态更新
如果你想不到解决办法,那么就再更大的范围内需求帮助。找到更多的团队成员,寻求更多的帮助,但是要快。
紧急事件过后,别忘了留出一些时间书写事故报告。
向过去学习,而不是重复它
- 没有什么比过去的事故记录是更好的学习材料了,公布和维护时候报告
- 在记录中请务必诚实,事务巨细,时刻寻找如何能在战术以及战略上避免这项事故的发生。
- 确保自己和其他人切实完成事故中总结的代办事项。
紧急事故管理
无流程管理的紧急事故
- 过于关注技术问题
- 沟通不畅
- 不请自来
事故总控、事务处理团队、发言人
什么时候对外宣布事故
- 是否需要引入第二个团队来帮助处理问题?
- 这次事故是否正在影响最终用户?
- 在集中分析一小时后,这个问题是否依然没有得到解决?
划分优先级:控制影响范围,恢复服务,同时为根源调查保存现场
事前准备:事先和所有事故处理参与者一起准备一套流程
信任:充分相信每个事故处理参与者,分配职责后让他们主动行动
反思:在事故处理过程中注意自己的情绪和精神状态。如果发现自己开始惊慌失措或者干到压力难以承受,应该需求更多的帮助
考虑替代方案:周期性地重新审视目前的情况,重新评估目前的工作是否应该继续执行,还是需要执行其他更要要或者更紧急的事情
练习:平时不断地使用这项流程,知道习惯成自然
换位思考:上次你是事故总控负责人吗?鼓励每个团队成员熟悉流程中的其他角色
事后总结:从失败中学习
- 避免指责,提供建设性意见
- 用户可见的宕机时间或者服务质量降低程度达到一定标准
- 任何类型的数据丢失
- on-call工程师需要人工介入的事故(包括回滚,切换用户流量等
- 问题解决耗时超过一定时间
- 监控问题(预示着问题是由人工发现的,而非报警系统)

