常见疑惑
什么是新鲜事 News Feed?
- 你登陆 Facebook / Twitter / 朋友圈 之后看到的信息流
- 你的所有朋友发的信息的集合
有哪些典型的新鲜事系统?
- 朋友圈
- RSS Reader
新鲜事系统的核心因素?
- 关注与被关注
- 每个人看到的新鲜事都是不同的
Storage 存储
Pull Model
Pull = 主动撩Ta
算法
- 在用户查看News Feed时,获取每个好友的前100条Tweets,合并出前100条News Feed
- K路归并算法 Merge K Sorted Arrays
复杂度分析
- News Feed => 假如有N个关注对象,则为N次DB Reads的时间 + N路归并时间(可忽略)
- Post a tweet => 1次DB Write的时间
Pull 原理图
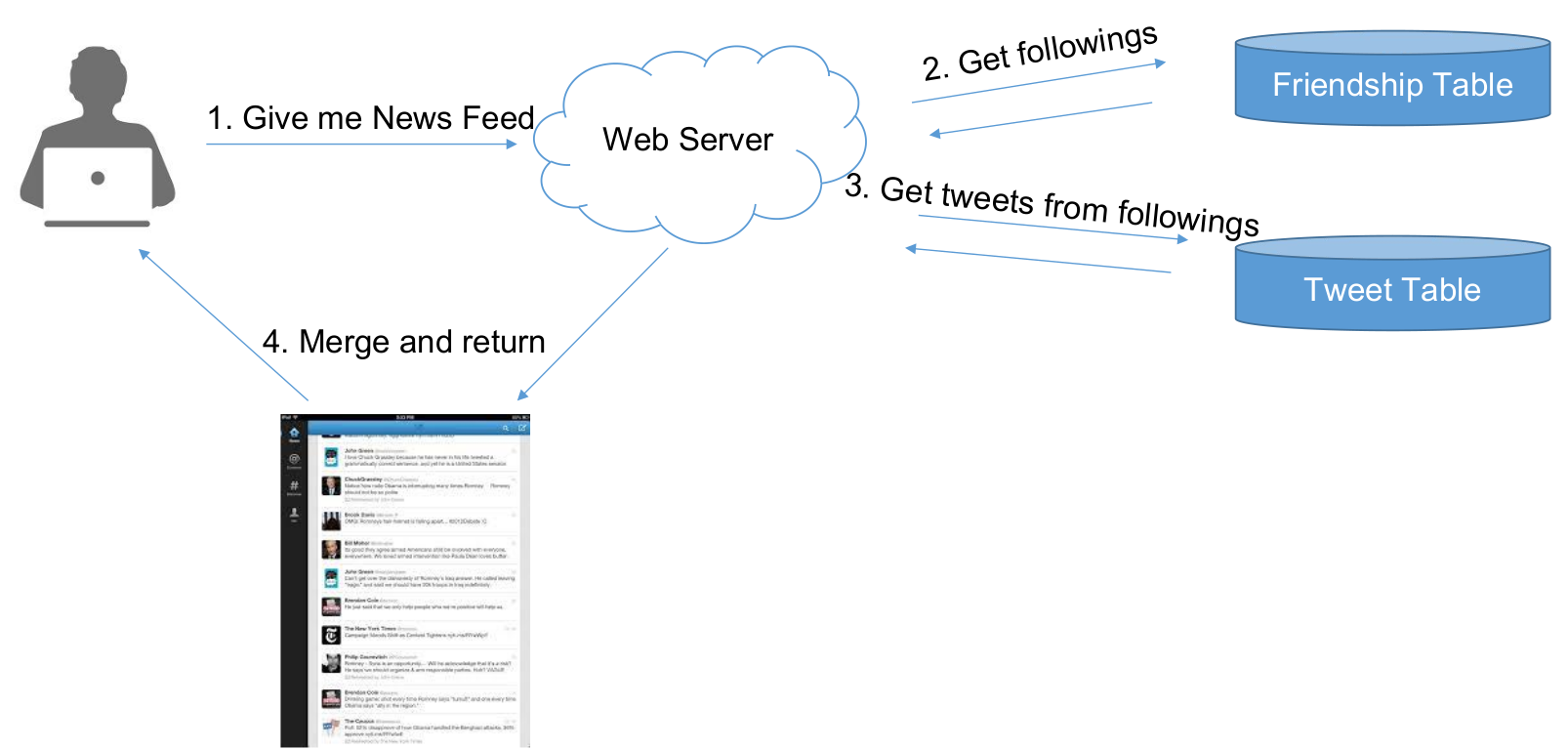
Pull模型有什么缺陷么?
1 | getNewsFeed(request) |
Push Model
Push = 坐等被撩
算法
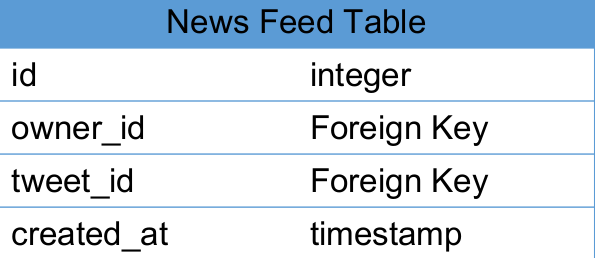
- 为每个用户建一个List存储他的News Feed信息
- 用户发一个Tweet之后,将该推文逐个推送到每个用户的News Feed List中
- 关键词:Fanout
- 用户需要查看News Feed时,只需要从该News Feed List中读取最新的100条即可
复杂度分析
- News Feed => 1次DB Read
- Post a tweet => N个粉丝,需要N次DB Writes
- 好处是可以用异步任务在后台执行,无需用户等待
Storage 存储 – News Feed Table
Push 原理图
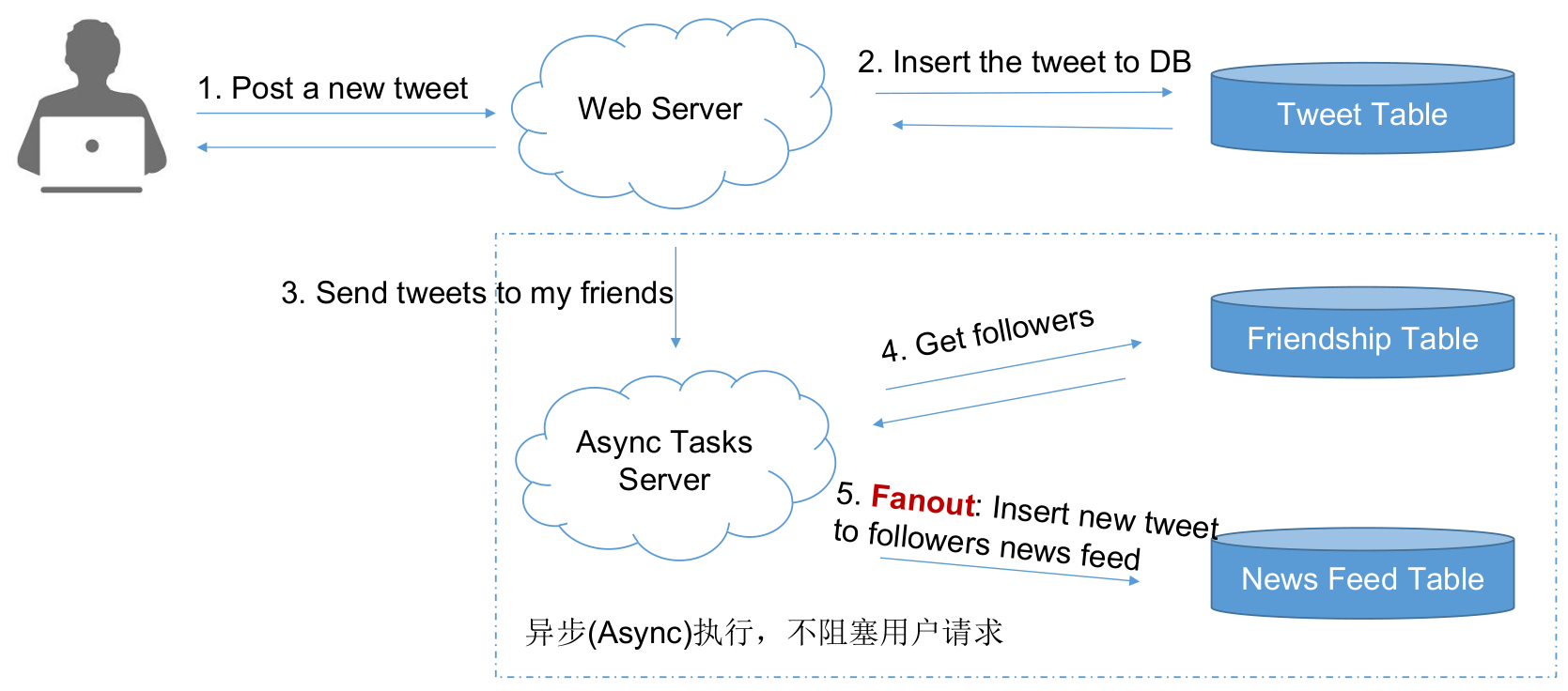
Push模型有缺陷么?
1 | getNewsFeed(request) |
Pull vs Push
热门Social App的模型
- Facebook – Pull
- Instagram – Push + Pull
- Twitter – Pull
- 朋友圈 - Push
误区
- 不坚定想法,摇摆不定
- 不能表现出Tradeoff的能力
- 无法解决特定的问题
4S分析
Scenario 场景
- 和面试官讨论
- 搞清楚需要设计哪些功能
- 并分析出所设计的系统大概所需要支持的 Concurrent Users / QPS / Memory / Storage 等
Service 服务
- 合并需要设计功能,相似的功能整合为一个Service
Storage 存储
对每个 Service 选择合适的存储结构
细化数据表单
画图展示数据存储和读取的流程
得到一个 Work Solution 而不是 Perfect Solution
这个Work Solution 可以存在很多待解决的缺陷
Scale 扩展
如何优化系统
第一步 Step 1: Optimize
- 解决设计缺陷 Solve Problems:Pull vs Push
- 更多功能设计 More Features:Like, Follow & Unfollow, Ads
- 一些特殊情况 Special Cases:xx搞挂微博, 僵尸粉
第二步 Step 2: Maintenance
- 鲁棒性 Robust:如果有一台服务器/数据库挂了怎么办
- 扩展性 Scalability:如果有流量暴增,如何扩展
解决Pull的缺陷
最慢的部分发生在用户读请求时(需要耗费用户等待时间)
1,在 DB 访问之前加入Cache
2,Cache 每个用户的 Timeline
N次DB请求 → N次Cache请求 (N是你关注的好友个数);
Trade off: Cache所有的?Cache最近的1000条?
3,Cache 每个用户的 News Feed
没有Cache News Feed的用户:归并N个用户最近的100条Tweets,然后取出结果的前100条;
有Cache News Feed的用户༚ 归并N个用户的在某个时间戳之后的所有Tweets
解决Push的缺陷
1,浪费更多的存储空间 Disk
- 与Pull模型将News Feed存在内存(Memory)中相比
- Push模型将News Feed存在硬盘(Disk)里完全不是个事儿
- Disk is cheap
2,不活跃用户 Inactive Users
- 粉丝排序 Rank followers by weight (for example, last login time)
3,粉丝数目 followers >> 关注数目 following
- Trade off: Pull + Push vs Pull
Push 结合 Pull 的优化方案
- 普通的用户仍然 Push
- 将 Lady Gaga 这类的用户,标记为明星用户
- 对于明星用户,不 Push 到用户的 News Feed 中
- 当用户需要的时候,来明星用户的 Timeline 里取,并合并到 News Feed 里
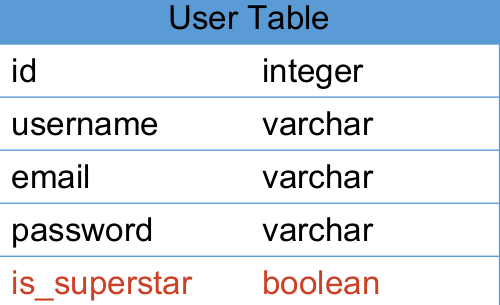
如何定义明星
- 明星不能在线动态计算,要离线计算
- 为 User 增加一个 is_superstar 的属性
- 一个用户被标记为 superstar 之后,就不能再被取消标记
Push和Pull的使用场景
什么时候用 Push?
资源少
想偷懒,少写代码
实时性要求不高
用户发帖比较少
双向好友关系,没有明星问题(比如朋友圈)
什么时候用 Pull ?
资源充足
实时性要求高
用户发帖很多
单向好友关系,有明星问题
通用问题 Common Questions
数据库服务器挂了怎么办?How to maintenance?
用户逐渐怎么怎么办?How to scale?
服务器顶不住压力怎么办?
数据库顶不住压力怎么办?
系统设计面试总结
4S
Scenario, Service, Storage, Scale,从这四个角度来分析
Ask before design
问清楚再动手设计,不要一上来就冲着一个巨牛的方案去设计,切忌不要做关键词大师
No more no less
不要总想着设计最牛的系统,要设计够用的系统
Work solution first
先设计一个基本能工作的系统,然后再逐步优化。
Done is better than perfect! —— Mark Zuckerberg
Analysis is important than solution
系统设计没有标准答案,记住答案是没用的,通过分析过程展示知识储备,权衡各种设计方式的利弊
拓展问题
果取关问题
如何实现 follow 与 unfollow?
- Follow 一个用户之后,异步地将他的 Timeline 合并到你的 News Feed 中
- Unfollow 一个用户之后,异步地将他发的 Tweets 从你的 News Feed 中移除
为什么需要异步 Async?
因为这个过程一点都不快
异步的好处?
用户迅速得到反馈,似乎马上就 follow / unfollow 成功了
异步的坏处?
- Unfollow 之后刷新 News Feed,发现好像他的信息还在
- 不过最终还是会被删掉的
如何存储 Likes?
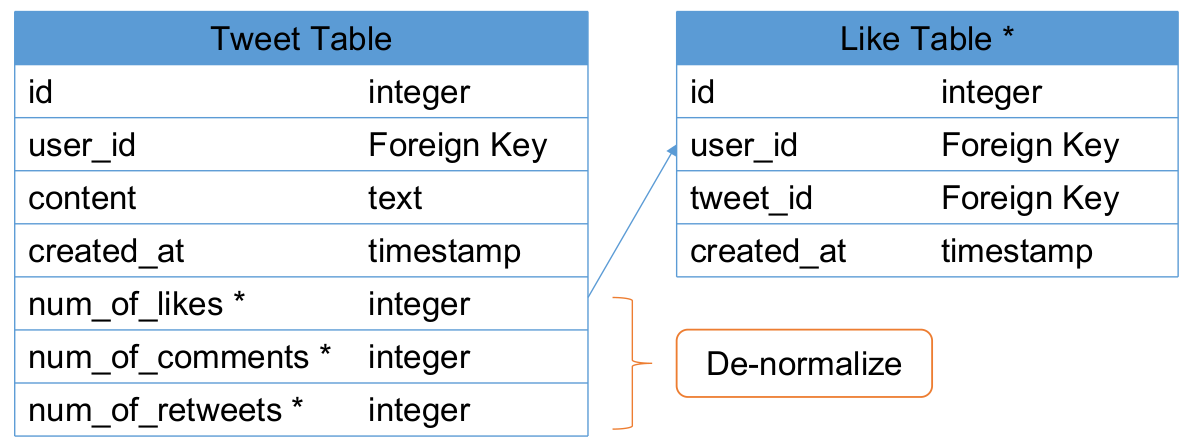
Normalize 获得点赞数的方式:SELECT COUNT * FROM like_table where tweet_id=xxx;
优点:标准化,最准确。
缺点:炒鸡慢,会增加 O(N) 个 SQL Queries(对于某一页的 Tweets,每个都得来这么一句查询)
Denormalize 获得点赞数的方式:
当有人点赞的时候:UPDATE like_table SET num_of_likes = num_of_likes + 1 where tweet_id = xxx
当有人取消赞的时候:UPDATE like_table SET num_of_likes = num_of_likes - 1 where tweet_id = xxx
想要获得一个 Tweet 的点赞数时,因为 num_of_likes 就存在 tweet 里,故无需额外的 SQL Queries
惊群现象 Thundering Herd
什么是惊群?
我们通常会使用缓存来作为数据库的“挡箭牌”,优化一些经常读取的数据的访问速度。即,在访问这些数据时,会先看看是否在缓存中,如果在,就直接读取缓存中的数据,如果不在,就从数据库中读取之后,写入缓存并返回。
那么在高并发的情况下,如果一条非常热的数据,因为缓存过期或者被淘汰算法淘汰等原因,被踢出缓存之后,会导致短时间内(<1s),大量的数据请求会出现缓存穿透(Cache miss),因为数据从 DB回填到 Cache 需要时间。从而这些请求都会去访问数据库,导致数据库处理不过来而崩溃,从而影响到其他数据的访问而导致整个网站崩溃。
解决办法及参考资料
Memcache Lease Get - 《Scaling Memcache at Facebook》http://bit.ly/1jDzKZK
Facebook 如何解决惊群效应的:https://bit.ly/1Q3t3P7
Redis 防雪崩架构设计 https://bit.ly/2KFneb5
QA
Cache是什么?
- 你可以认为相当于算法中的HashMap
- 是Key-value的结构
Cache存在哪儿?
- Cache存在内存里
常用的Cache工具/服务器有什么?
- Memcached
- Redis
为什么需要用Cache?
- Cache因为是内存里,所以存取效率比DB要高
为什么不全放Cache里?
- 内存中的数据断电就会丢失
- Cache 比硬盘贵
News Feed 和 Timeline 的定义和区别?
News Feed:新鲜事,我朋友+我发的所有帖子按照某种顺序排列的整合(比如按照时间排序)
用户打开Twitter之后首先看到的界面就是News Feed界面,这些 tweets 来自你关注的用户
Timeline:某个用户发的所有帖子
用户点开某个人的页面之后,看到这个人发的所有帖子
在有的系统中,这两个概念的定义会完全反过来,这里我们统一按照上面的定义。
什么是消息队列
- 简单的说就是一个先进先出的任务队列列表
- 做任务的worker进程共享同一个列表
- Workers从列表中获得任务去做,做完之后反馈给队列服务器
- 队列服务器是做异步任务必须有的组成部分
哪些工具可以做消息队列
最常用的有 RabbitMQ, ZeroMQ, Redis, Kafka
NewsFeed Table 中 Pull Model 和 Push Model 的区别?
http://www.jiuzhang.com/qa/2074/
http://www.jiuzhang.com/qa/2031/
http://www.jiuzhang.com/qa/1741/
NewsFeed 如何实现 Pagination?
http://www.jiuzhang.com/qa/1839/

