首先,我们以之前实践过的nginx-deployment.yaml文件为例:
1 | apiVersion: apps/v1 |
这个Deployment定义的编排动作是:请确保携带了app:nginx标签的Pod的个数永远等于spec.replicas指定的个数-> 2。
这就意味着,如果在这个集群中,携带app:nginx标签的Pod个数大于等于2,就会有旧的Pod被删除;反之就会有新的Pod被创建。
那么,究竟是Kubernetes项目的哪个组件在执行这些操作呢?——kube-controller-manager组件。
实际上,这个组件就是一系列控制器的集合,看下pkg/controller目录
实际上,这些控制器之所以被统一放在pkg/controller目录下,就是因为它们都遵循Kubernetes项目中的一个通用编排模式——控制循环(control loop)。
比如,现在有一种待编排的对象X,它有一个对应的控制器。那么,我就可以用一段Go语言风格伪代码来描述:
1 | for { |
我们以Deployment为例,简单介绍它对控制器模型的实现:
- 1,
Deployment控制器从etcd中获取所有携带了app:nginx标签的Pod,然后统计它们的数量,这就是实际状态; - 2,
Deployment对象的Replicas字段的值就是期望状态; - 3,
Deployment控制器比较两个状态,然后根据结果确定是创建Pod,还是删除已有的Pod。
因此,一个Kubernetes对象的主要编排逻辑在第三步对比阶段完成。这个操作通常称作调谐(reconcile)。调谐的过程则称作调谐循环(reconcile loop)或者同步循环(sync loop)。
调谐的最终结果往往是对被控制对象的某种写操作。比如,增加/删除 Pod,或者更新Pod的某个字段。
至此,我们可以对Deployment以及其他类似的控制器做一个简单总结: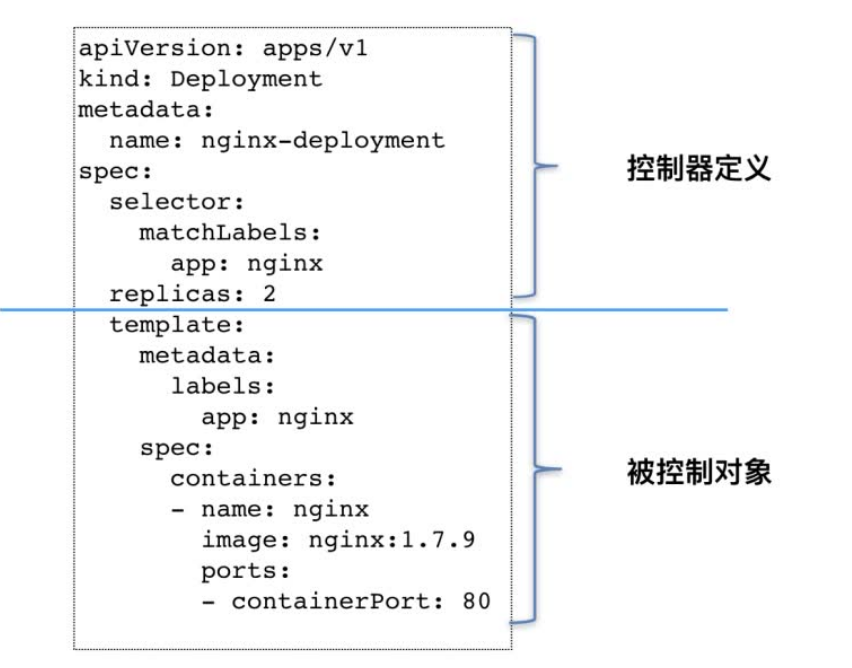
类似于Deployment这样的控制器,由上半部分的控制器定义(包括期望状态)和下半部分的被控制对象的模板组成的。这就是为什么在所有API对象的Metadata里,都会有一个名为ownerReference的字段,用于保存当前这个API对象的拥有者的信息。

