本文将开始系统学习Kubernetes的编排原理,因此先从最重要最基本的Pod开始。
为什么需要Pod
首先需要记住:
Pod是Kubernetes项目的院子调度单位;Namespace做隔离,Cgroups做限制,rootfs做文件系统- 容器的本质是进程,
Kubernetes的本质是操作系统。
Pod的实现原理
首先需要明白:Pod只是一个逻辑概念,也就是说,Kubernetes真正处理的还是宿主机操作系统上Linux容器的Namespace和Cgroups,并不存在所谓的Pod的边界或者隔离环境。
那么Pod又是怎么被“创建”出来的呢?——Pod其实是一组共享了某些资源的容器。Pod里的所有容器都共享一个Network Namespace,并且可以声明共享同一个Volume。
问题1
这么说来,一个有A、B两个容器的Pod,不就等同于一个容器(容器A)共享另外一个容器(容器B)的网络和Volume的做法吗?
这好像通过docker run --net --volumes-from这样的命令就可以实现,比如:
1 | docker run --net=B --volumes-from=B --name=A image-A ... |
但是,如果容器B就必须比容器A先启动,这样一个Pod里的多个容器就不是对等关系,而是拓扑关系。
问题1解答
所以,在Kubernetes项目里,Pod的实现需要使用一个中间容器,这个容器叫作Infra容器。在这个Pod中,Infra容器永远是第一个被创建的容器,用户定义的其他容器则通过Join Network Namespace的方式与Infra容器关联在一起。
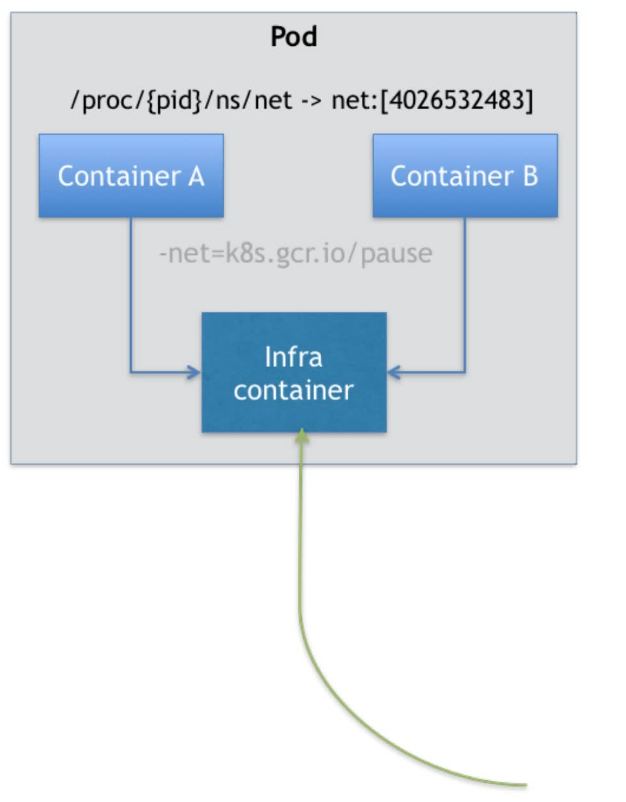
如上图所示,这个Pod里有两个用户容器A和容器B,还有一个Infra容器。
在Kubernetes项目里,Infra容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作k8s.gcr.io/pause。这个镜像是用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有100~200KB。
在Infra容器“hold” Network Namespace后,用户容器就可以加入Infra容器的Network Namespace中了。这也意味着,对于Pod里的容器A和容器B来说:
- 它们可以直接使用
localhost进行通信; - 它们“看到”的网络设备跟
Infra容器“看到”的完全一样; - 一个
Pod只有一个IP地址,也就是这个Pod的Network Namespace对应的IP地址; - 当然,其他所有网络资源都是一个
Pod一份,并且被该Pod中所有容器共享; Pod的生命周期只跟Infra容器一致,而与容器A和容器B无关。
而对于同一个Pod里的所有用户容器来说,它们的进出流量也可以都是通过Infra容器完成的。
有了这个设计之后,Kubernetes项目只要把所有Volume的定义都设计在Pod层级,就可以实现共享Volume。一个Volume对应的宿主机目录对于Pod来说只有一个,Pod里的容器只要声明挂载这个Volume,就一定可以共享这个Volume对应的宿主机目录。例如:
1 | apiVersion: v1 |
在这个例子中,debian-container和nginx-container都声明挂载了shared-data这个Volume。而shared-data是hostPath类型,所以它在宿主机上对应的目录就是/data。而这个目录其实被同时绑定挂载进了debian-container和nginx-container两个容器。
这就是nginx-container可以从它的/usr/share/nginx/html目录读取到debian-container生成的index.html文件的原因。
Pod的本质
Pod实际上是在扮演传统基础设施里“虚拟机”的角色,容器则是这个虚拟机里运行的用户程序。
所以,当你需要把一个在虚拟机里运行的应用迁移到Docker容器中时,一定要分析到底哪些进程或组件在这个虚拟机里运行,然后就可以把整台虚拟机想象成Pod,把这些进程分别做成容器镜像,把有顺序关系的容器定义为Init Container。这是从传统应用架构到微服务架构最自然的过渡方式。
深入解析Pod对象
首先需要我们得出的结论:Pod扮演的是传统部署环境中“虚拟机”的角色。这样的设计是为了让用户从传统环境(虚拟机环境)向Kubernetes(容器环境)的迁移更加平滑。
Pod中重要字段的含义和用法
NodeSelector
一个供用户将Pod与Node进行绑定的字段。
1 | apiVersion: v1 |
此配置意味着Pod永远只能在携带了disktype: ssd标签的节点上运行,否则它将调度失败。
NodeName
一旦Pod的这个字段被赋值,Kubernetes项目就会认为这个Pod已调度,调度的结果就是赋值的节点名称。
注:该字段一般由调度器负责设置,但用户也可以设置它来骗过调度器。
HostAliases
定义了Pod的hosts文件(比如/etc/hosts)里的内容。
1 | apiVersion: v1 |
设置了一组IP和hostname的数据,当这个Pod启动后,/etc/hosts文件的内容将如下所示:
1 | cat /etc/hosts |
注意:在Kubernetes项目中,如果要设置hosts文件里的内容,一定要通过这种方法;而如果直接修改了hosts文件,在Pod被删除重建之后,kubelet会自动覆盖被修改的内容。
Containers的ImagePullPolicy
定义了镜像拉取的策略。
ImagePullPolicy的默认值是Always,即每次创建Pod都重新拉取一次镜像,另外,当容器的镜像类似于nginx或者nginx:latest这样的名字时,ImagePullPolicy也会被认为Always。
如果ImagePullPolicy的值被定义为Never或者IfNotPresent,则意味着Pod永远不会主动拉取这个镜像,或者只在宿主机上不存在这个镜像时才拉取。
Containers的Lifecycle
定义的是Container Lifecycle Hooks。
它的作用是在容器状态发生变化时出发一系列“钩子”,例如:
1 | apiVersion: v1 |
在容器成功启动之后,我们在/usr/share/message里写入一句“欢迎信息”,而在这个容器被删除之前,我们先调用了Nginx的退出指令,从而实现了容器的“优雅退出”。
Pod对象在Kubernetes中的生命周期
Pod生命周期的变化主要体现在Pod API对象的Status部分,这是它除Metadata和Spec外第三个重要字段。其中pod.status.phase就是Pod的当前状态,它有如下几种可能的情况:
Pending。这个状态意味着Pod的YAML文件已经提交给了Kubernetes,API对象已经被创建并保存到etcd中。但是这个Pod里有些容器因为某种原因不能被顺利创建。比如,调度不成功。Running。这个状态下,Pod已经调度成功,跟一个具体的节点绑定。它包含的容器都已经创建成功,并且至少有一个正在运行。Successed。这个状态意味着Pod里所有容器都正常运行完毕,并且已经退出了。这种情况在运行一次性任务时最为常见。Failed。这个状态下,Pod里至少有一个容器以不正常的状态(非0的返回码)退出。出现这个状态意味着需要想办法调试这个容器的应用,比如查看Pod的Events日志。Unknown。这是一个异常状态,意味着Pod的状态不能持续地被kubelet汇报给kube-apiserver,这很有可能是主从节点(Master和kubelet)间的通信出了问题。
Pod对象使用进阶
本节将从一种特殊的Volume(Projected Volume)开始,带你更加深入地理解Pod对象各个重要字段的含义。
目前为止,Kubernetes支持的常用Projected Volume共有以下4种
Secret
帮你把Pod想要访问的加密数据存放到etcd中,你就可以通过在Pod的容器里挂载Volume的方式访问这些Secret里保存的信息了。
典型场景:存放数据库的Credential信息
1 | apiVersion: v1 |
以Secret对象的方式交给Kubernetes保存,完成这个操作的指令如下:
1 | cat ./username.txt |
username.txt和password.txt文件里存放的就是用户名和密码,user和pass则是我为Secret对象指定的名字。而想要查看这些Secret对象的话,则只要执行一条kubectl get命令即可: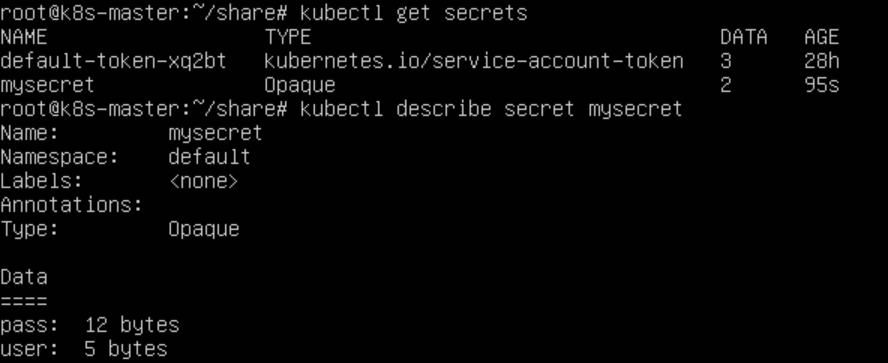
除了kubectl create secret指令,也可以直接通过编写YAML文件来创建这个Secret对象,比如:
1 | apiVersion: v1 |
ConfigMap
ConfigMap保存的是无须加密的、应用所需的配置信息。除此之外,ConfigMap的用法几乎与Secret完全相同。
你可以使用kubectl create configmap从文件或者目录创建ConfigMap,也可以直接编写ConfigMap对象的YAML文件。
Download API
Download API的作用是让Pod里的容器能够直接获取这个Pod API对象本身的信息。
1 | apiVersion: v1 |
支持的字段
使用fieldRef可以声明使用:
- metadata.name——Pod的名词
- metadata.namespace——Pod的Namespace
- metadata.uid——Pod的UID
- metadata.labels[‘
‘]——指定 上的 Label值 - metadata.annotations——Pod的所有Annotation
使用resourceFieldRef可以声明使用:
- 容器的CPU limit;
- 容器的CPU request;
- 容器的memory limit;
- 容器的memory request;
- 容器的ephemeral-strorage limit;
- 容器的ephemeral-strorage request。
通过环境变量声明使用:
- status.podIP——Pod的IP
- spec.serviceAccountName——Pod的ServiceAccount名词
- spec.nodeName——Node的名字
- status.hostIP——Node的IP
ServiceAccountToken
ServiceAccount对象的作用是Kubernetes系统内置的一种“服务账户”,它是Kubernetes进行权限分配的对象。比如Service Account A可以只被允许对Kubernetes API进行GET操作,而Service Account B可以有Kubernetes API的所有操作的权限。
像这样的Service Account的授权信息和文件,实际上保存在它所绑定的一个特殊的Secret对象里。这个特殊的Secret对象叫作ServiceAccountToken。任何在Kubernetes集群上运行的应用,都必须使用ServiceAccountToken里保存的授权信息(也就是Token),才可以合法地访问API Server。
因此,ServiceAccountToken也可以理解为一种特殊的Secret。
容器健康检查和恢复机制
在Kubernetes中,可以为Pod里的容器定义一个健康检查“探针”(Probe)。这样的,kubelet就会根据Probe的返回值决定这个容器的状态,而不是直接以容器是否运行(来自Docker返回的信息)作为依据。这种机制是生产环境中保证应用健康的重要手段。
例子:
1 | apiVersion: v1 |
执行命令,创建Pod:
1 | kubectl create -f liveness.yaml |
查看这个Pod的状态:
30秒之后再查看一下Pod的Events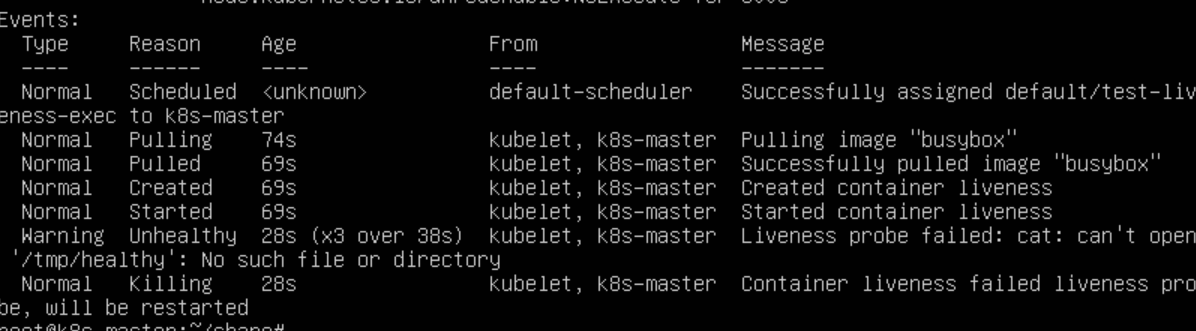
发现已经报告了异常,tmp/healthy文件不存在了,然而Pod的状态仍然是Running。为什么?
因为Kubernetes中没有Docker的Stop语义。所以虽说是Restart,实际上却是重新创建了容器。
这个功能就是Kubernetes里的Pod恢复机制,也叫restartPolicy。它是Pod的Sepc部分的一个标准字段(pod.spec.restartPolicy),默认值是Always,即无论这个容器何时发生异常,它一定会被重启。
总结
本文重点介绍了Pod相关的内容,有Pod实现原理,本质,Pod重要字段的含义和用法,以及声明周期,还有实践“容器健康检查”机制,最后又引出了Kubernetes的Pod恢复机制。
总Pod是学习Kubernetes很重要的一环,后期还需要多实践,体会用法。

