什么是StatefulSet
在分布式应用中,它的多个实例之间往往有依赖关系,比如主从关系、主备关系;还有数据存储类应用,它的多个实例往往会在本地磁盘上保存一份数据,而这些实例一旦被结束,即便重建出来,实例与数据之间的对应关系也已经丢失,从而导致应用失败。
所以,这种实例之间有不对等关系,以及实例对外部数据有依赖关系的应用,就称为有状态应用(stateful application)。
得益于控制器模式的设计思想,Kubernetes项目在Deployment基础上扩展出了对有状态应用的初步支持。这个编排功能就是StatefulSet。
拓扑状态
应用的多个实例之间不是完全对等的。这些应用实例必须按照某种顺序启动,比如应用的主节点A要先于从节点B启动。而如果删除A和B两个Pod,它们再次被创建出来时也必须严格按照这个顺序执行。并且,新创建出来的Pod必须和原来Pod的网络标识一样,这样原先的访问者才能使用同样的方法访问到这个新Pod。
Headless Service
Service是Kubernetes项目中用来将一组Pod暴露给外界访问的一种机制。
Service如何被访问
- 1,以
Service的VIP(virtualIP,虚拟IP)方式。比如,当我访问10.0.23.1这个Service的IP地址时,10.0.23.1其实就是一个VIP,它会把请求转发到该Service所代理的某一个Pod上。 - 2,以
Service的DNS方式。比如,此时我只要访问my-svc.my-namespace.svc.cluster.local这条DNS记录,就可以访问到名叫my-svc的Service所代理的某一个Pod。
在第二种Service DNS的方式下,具体又可以分为两种处理办法:
- (1)
Normal Service:在这种情况下,你访问my-svc.my-service.svc.cluster.local解析到的,正是my-svc这个Service的VIP,后面的流程就跟VIP方式一致了。 - (2)
Headless Service:在这种情况下,你访问my-svc.my-service.svc.cluster.local解析到的,直接就是my-svc代理的某一个Pod的IP地址。这里的区别在于,Headless Service不需要分配一个VIP,而是可以直接以DNS记录的方式解析出被代理Pod的IP地址。
Headless Service定义
标准的Headless Service对应的YAML文件:
1 | apiVersion: v1 |
因此Headless Service的含义是这个Service没有一个VIP作为 “头”。
所以,这个Service被创建后并不会被分配VIP,而是会以DNS记录的方式暴露出它所代理的Pod。而它所代理的Pod,依然是通过Label Selector机制选出的,即所有携带了app: nginx标签的Pod都会被这个Service代理。
当你按照这样的方式创建了一个Headless Service之后,它所代理的所有Pod的IP地址都会被绑定一个如下格式的DNS记录:
1 | <pod-name>.<svc-name>.<namespace>.svc.cluster.local |
这个DNS记录,正是Kubernetes项目为Pod分配的唯一可解析身份(resolvable idenetity)。
StatefulSet如何使用DNS记录来维持Pod的拓扑状态
编写一个StatefulSet的YAML文件:
1 | apiVersion: apps/v1 |
通过kubectl create -f创建,查看对象: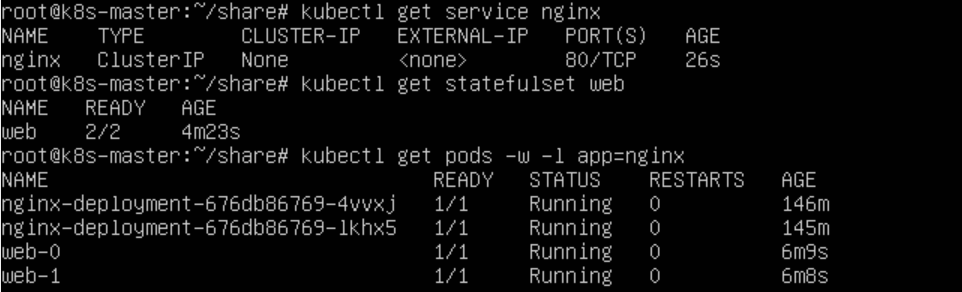
从上面这个Pod的创建过程可以看出,StatefulSet给它所管理的所有Pod的名字进行了编号,编号规则是:-。而且这些编号都是从0开始累加的,与StatefulSet的每个Pod实例一一对应,绝不重复。
而且,这些Pod的创建也是严格按照编号顺序进行的。比如web-0进入Running
状态,并且细分状态变为Ready之前,web-1会一直处于Pending状态。
使用kubectl exec进入容器查看它们的hostname:
可以看到这两个Pod的hostname与Pod名字是一致的,都被分配了对应的编号。
我们再试着以DNS方式访问这个Headless Service:
1 | # 启动了一个一次性Pod |
在这个Pod里面,我们尝试用nslookup命令解析Pod对应的Headless Service: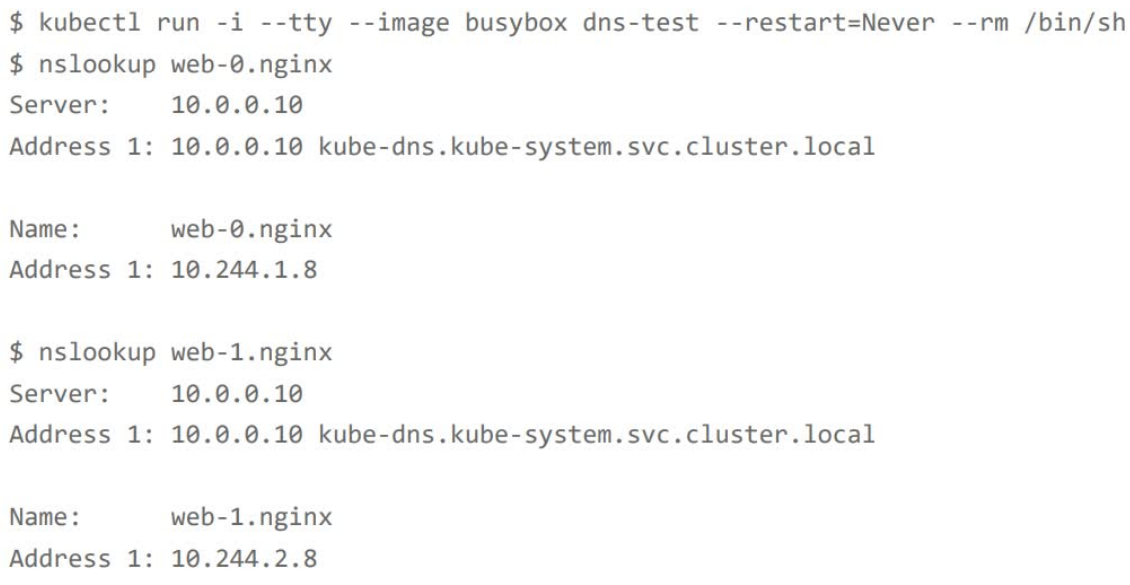
当我们把这两个有状态应用的Pod删掉: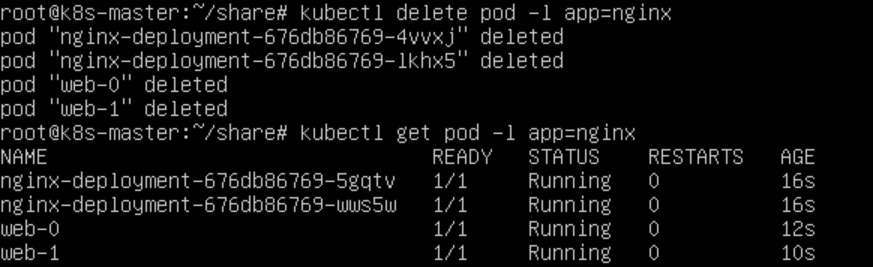
可以看到,Kubernetes会按照原先编号的顺序重新创建出两个Pod,并且分配了原来相同的网络身份。
这样StatefulSet就保证了Pod网络标识的稳定性。
存储状态
StatefulSet 对存储状态的管理机制,主要使用的是一个叫作 Persistent Volume Claim 的功能。
应用的多个实例分别绑定了不同的存储数据。对于这些应用实例来说,Pod A第一次读取到的数据和隔了10分钟之后再次读取到的数据应该是同一份,哪怕在此期间Pod A被重新创建过。典型例子:一个数据库应用的多个存储实例。
有状态应用实践
总结
StatefulSet的核心功能,就是通过某种方式记录这些状态,然后在Pod被重新创建时,能够为新Pod恢复这些状态。StatefulSet这个控制器的主要作用之一,就是使用Pod模板创建Pod时对它们进行编号,并且按照编号的顺序逐一完成创建工作。而当StatefulSet的“控制循环”发现Pod的实际状态与期望状态不一致,需要新建或者删除Pod以进行“调谐”时,它会严格按照这些Pod编号的顺序逐一完成这些操作。

