PV和PVC
PV是持久化存储数据卷。
这个API对象主要定义的是一个持久化存储在宿主机上的目录,比如一个NFS的挂载目录。
下面来定义一个NFS类型的PV:
1 | apiVersion: v1 |
PVC描述的是Pod所希望使用的持久化存储的属性。比如Volume存储的大小、可读写权限。
PVC对象通常由平台的用户创建,或者以PVC模板的方式为StatefulSet的一部分,然后由StatefulSet控制器负责创建带编号的PVC。比如,用户可以声明一个1GB大小的PVC:
1 | apiVersion: v1 |
用户创建的PVC要真正被容器使用,就必须先和某个符合条件的PV进行绑定。这里要检查两个条件:
- 1,
PV和PVC的spec字段:比如PV的存储大小必须满足PVC要求; - 2,
PV和PVC的storageClassName字段必须一样。
在成功将PVC和PV绑定之后,Pod就可以像使用hostPath等常规类型的Volume一样在自己的YAML文件里声明使用这个PVC:
1 | apiVersion: v1 |
这个YAML文件描述的是:在volumes字段里声明自己要使用的PVC名字,然后等Pod创建之后,kuberlet就会把该PVC所对应的PV——一个NFS类型的Volume挂载在这个Pod容器内的目录上。
可以看出,PVC和PV设计跟“面对对象”的思想非常相似——可以把PVC理解为持久化存储的“接口”,它提供了对某种持久化存储的描述,但不提供具体的实现;实现是由PV负责完成。
Volume Controller
在Kubernetes中存在一个专门处理持久化存储的控制器,叫作Volume Controller。
PersistentVolumeController
PersistentVolumeController会不断查看当前每一个PVC是否已经处于Bound状态,如果不是,它会遍历所有可用的PV,并尝试将其与这个“单身”的PVC进行绑定,这样Kubernetes就可以保证用户提交的每一个PVC只要有合适的PV出现,就能很快地进入绑定状态。
PV与PVC绑定是什么意思?
将PV对象的名字填在PVC对象的spec.volumeName字段上。
所以Kubernetes只要获取这个PVC对象,就一定能找到它所绑定的PV。
这个PV对象是如何变成容器里的一个持久化存储呢?
首先,容器的Volume,其实就是将一个宿主机上的目录跟一个容器里的目录绑定挂载在了一起。
所谓的持久化Volume,指的就是该宿主机上的目录具备“持久性”,即该目录里面的内容既不会因为容器的删除而被清理,也不会跟当前的宿主机绑定。当容器重启或在其他节点上重建之后,它仍能通过挂载这个Volume访问到这些内容。
所以,大多数情况下,持久化Volume的实现往往依赖一个远程存储服务,比如远程文件存储,远程块存储等;而Kubernetes需要做的是使用这些存储服务来为容器准备一个持久化的宿主机目录,以供将来进行绑定挂载时使用。所谓“持久化”,指的是容器在该目录里写入的文件都会保存在远程存储中,从而使该目录具备了“持久性”。
“持久化”宿主机的过程(处理PV的具体原理)
第一阶段-Attach
当一个Pod调度到一个节点上之后,kubelet就要负责为这个Pod创建它的Volume目录。默认情况下,kubelet为Volume创建的目录是一个宿主机上的路径,比如:
1 | /var/lib/kubelet/pods/<Pod 的ID>/volumes/kubernetes.io-<Volume 类型>/<Volume 名字> |
如果你的Volume类型是远程块存储,比如Google Cloud的Persistent Disk,那么kubelet需要先调用Google Cloud的API,将它提供的Persistent Disk挂载到Pod所在的宿主机上。相当于执行:
1 | gcloud compute instances attach-disk <虚拟机名字> --disk <远程磁盘名字> |
这一步为虚拟机挂载远程磁盘的操作。
如果你的Volume类型是远程文件存储,直接进入第二阶段。
第二阶段-Mount
kubelet格式化这个磁盘设备,然后把它挂载到宿主机指定的挂载点上。
疑惑:Kubernetes如何定义和区分这两个阶段的呢?
在具体的Volume插件的实现接口上,Kubernetes分别给这两个阶段提供了不同的参数列表:
- 第一阶段:
Kubernetes提供的可用参数是nodeName-宿主机的名字; - 第二阶段:
Kubernetes提供的可用参数是dir-Volume的宿主机目录。
Storage Class
由于PV 这个对象是由运维人员创建完成的,但是,在大规模的生产环境里,这其实是一个非常麻烦的工作。因为一个大规模的 Kubernetes 集群里很可能有成千上万个 PVC,这就意味着运维人员必须得事先创建出成千上万个 PV。更麻烦的是,随着新的 PVC 不断被提交,运维人员就不得不继续添加新的、能满足条件的 PV,否则新的 Pod 就会因为 PVC 绑定不到 PV而失败。在实际操作中,这几乎没办法靠人工做到。
所以,Kubernetes 为我们提供了一套可以自动创建 PV 的机制,即:Dynamic
Provisioning。
Dynamic Provisioning 机制工作的核心,在于一个名叫 StorageClass 的 API 对象。
而 StorageClass 对象的作用,就是创建 PV 的模板。具体地说StorageClass对象会定义如下两个部分内容:
- 第一,PV 的属性。比如,存储类型、Volume 的大小等等。
- 第二,创建这种 PV 需要用到的存储插件。比如,Ceph 等等。
有了这样两个信息之后,Kubernetes 就能够根据用户提交的 PVC,找到一个对应的
StorageClass 了。然后,Kubernetes 就会调用该 StorageClass 声明的存储插件,创建出需要的 PV。
总结
PV,PVC,StorageClass之间的关系: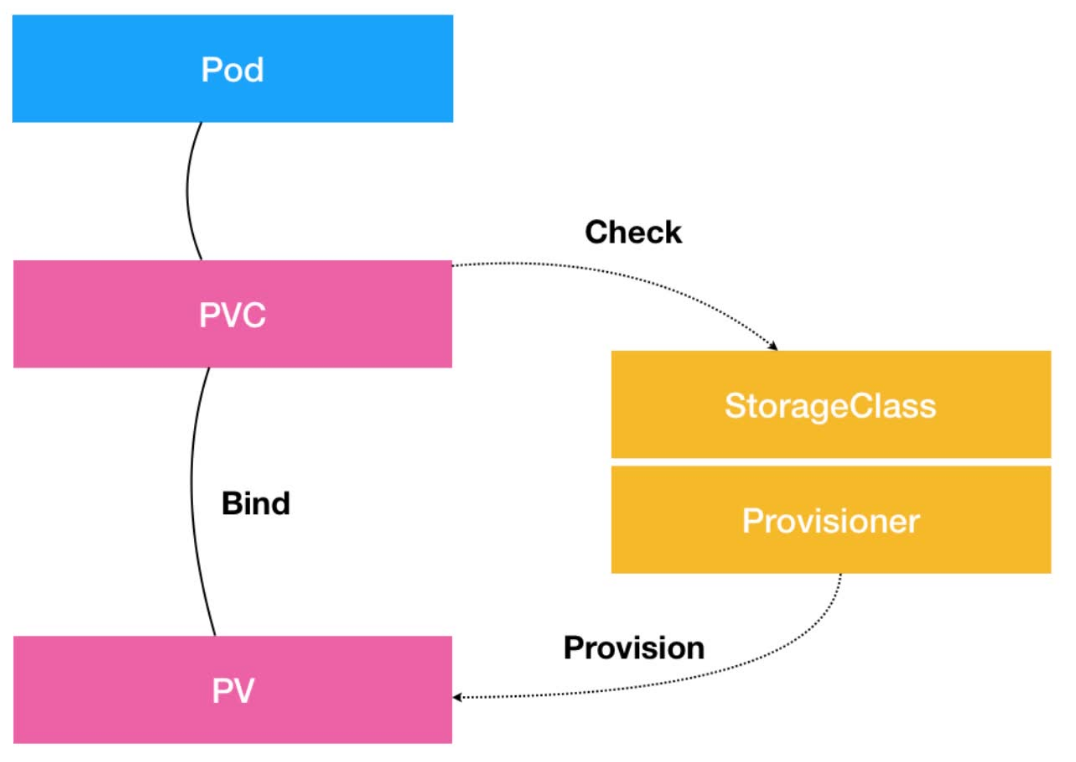
PVC描述的是Pod想使用的持久化存储的属性,比如存储的大小、读写权限等;PV描述的则是一个具体的Volume的属性,比如Volume的类型、挂载目录、远程存储服务器地址等;StorageClass的作用则是充当PV的模板,并且只有同属于一个StorageClass的PV和PVC才可以绑定在一起;StorageClass的另一个重要作用是指定PV的Provisioner(存储指针)。此时,如果你的存储插件支持Dynamic Provisioning,Kubernetes就可以自动为你创建PV。

