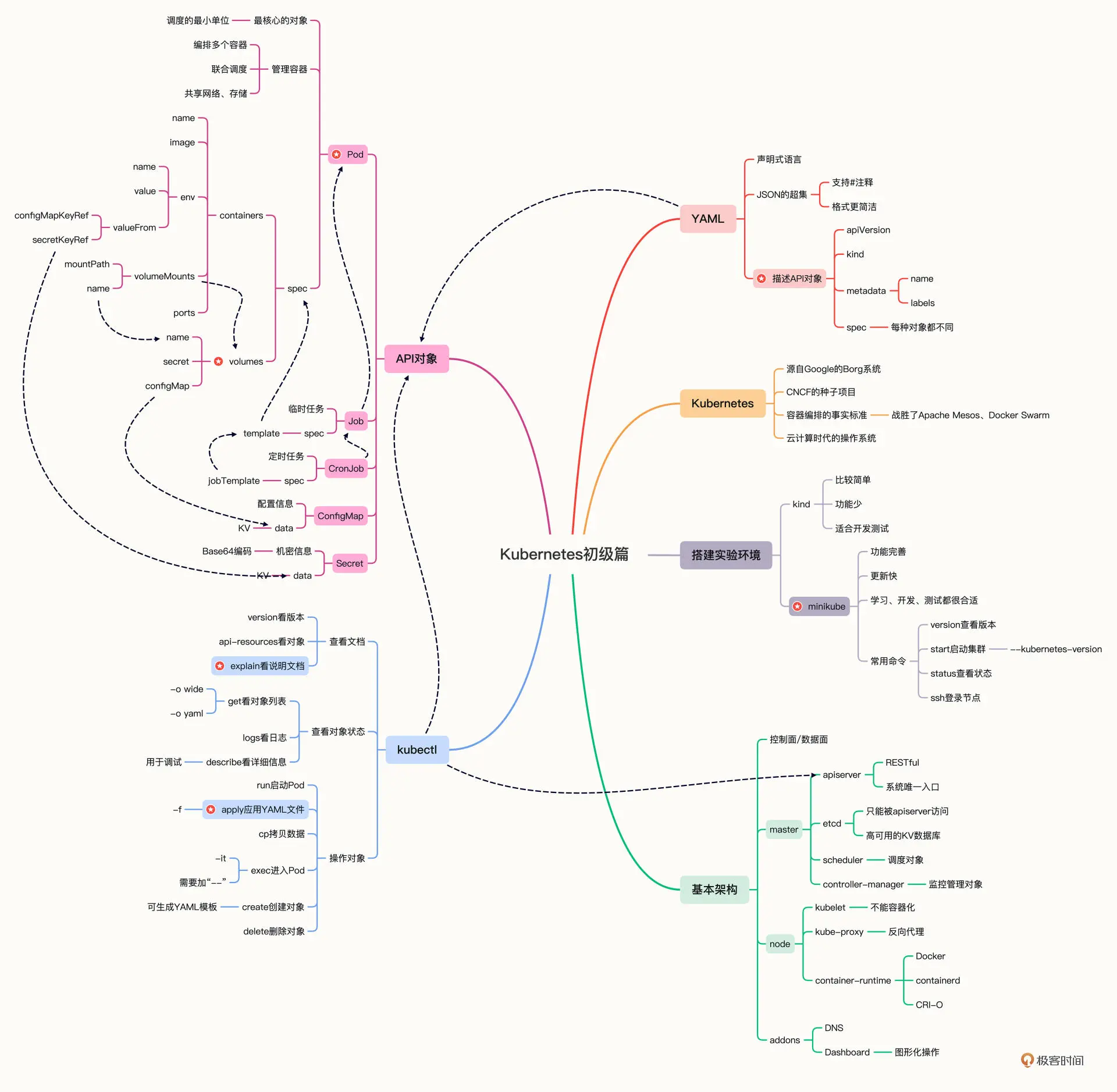
架构图
本文我将尝试用Kubernetes集群上搭建一个WordPress网站,他们的内部逻辑关系如下:
搭建步骤
编排 MariaDB 对象
MariaDB需要4个环境变量,比如数据库名、用户名、密码等,在Docker里我们是在命令行里使用参数--env,而在Kubernetes里我们就应该使用ConfigMap,为此需要定义一个maria-cm对象:
1 | apiVersion: v1 |
然后我们定义Pod对象maria-pod,把配置信息注入Pod,让MariaDB运行时从环境变量读取这些信息:
1 | apiVersion: v1 |
使用kubectl apply创建:
1 | # kubectl apply -f maria-cm.yml |
现在数据库就成功地在 Kubernetes 集群里跑起来了,IP 地址是“172.17.0.5”,注意这个地址和 Docker 的不同,是 Kubernetes 里的私有网段。
编排 WordPress 对象
先用 ConfigMap 定义它的环境变量:
1 | apiVersion: v1 |
然后我们再编写 WordPress 的 YAML 文件:
1 | apiVersion: v1 |
用 kubectl apply 创建对象:
1 | # kubectl apply -f wp-cm.yml |
为 WordPress Pod 映射端口号,让它在集群外可见
因为Pod都是运行在Kubernetes内部的私有网段里的,外界无法直接访问,想要对外暴露服务,需要使用一个专门的kubectl port-forward命令,它专门负责把本机的端口映射到在目标对象的端口号,有点类似Docker的参数-p,经常用于Kubernetes的临时调试和测试。
我们把本地的“8080”映射到 WordPress Pod 的“80”,kubectl 会把这个端口的所有数据都转发给集群内部的 Pod:
1 | # kubectl port-forward wp-pod 8080:80 & # 让端口转发工作在后台进行 |
如果想关闭端口转发,需要敲命令 fg ,它会把后台的任务带回到前台,然后就可以简单地用“Ctrl + C”来停止转发了。
创建反向代理的 Nginx,让我们的网站对外提供服务
因为 WordPress 网站使用了 URL 重定向,直接使用“8080”会导致跳转故障,所以为了让网站正常工作,我们还应该在 Kubernetes 之外启动 Nginx 反向代理,保证外界看到的仍然是“80”端口号。
Nginx 的配置文件:
1 | server { |
然后我们用 docker run -v 命令加载这个配置文件,以容器的方式启动这个 Nginx 代理:
1 | docker run -d --rm --net=host -v `pwd`/wp.conf:/etc/nginx/conf.d/default.conf nginx:alpine |
有了 Nginx 的反向代理之后,我们就可以打开浏览器,输入本机的“127.0.0.1”看到 WordPress 的界面: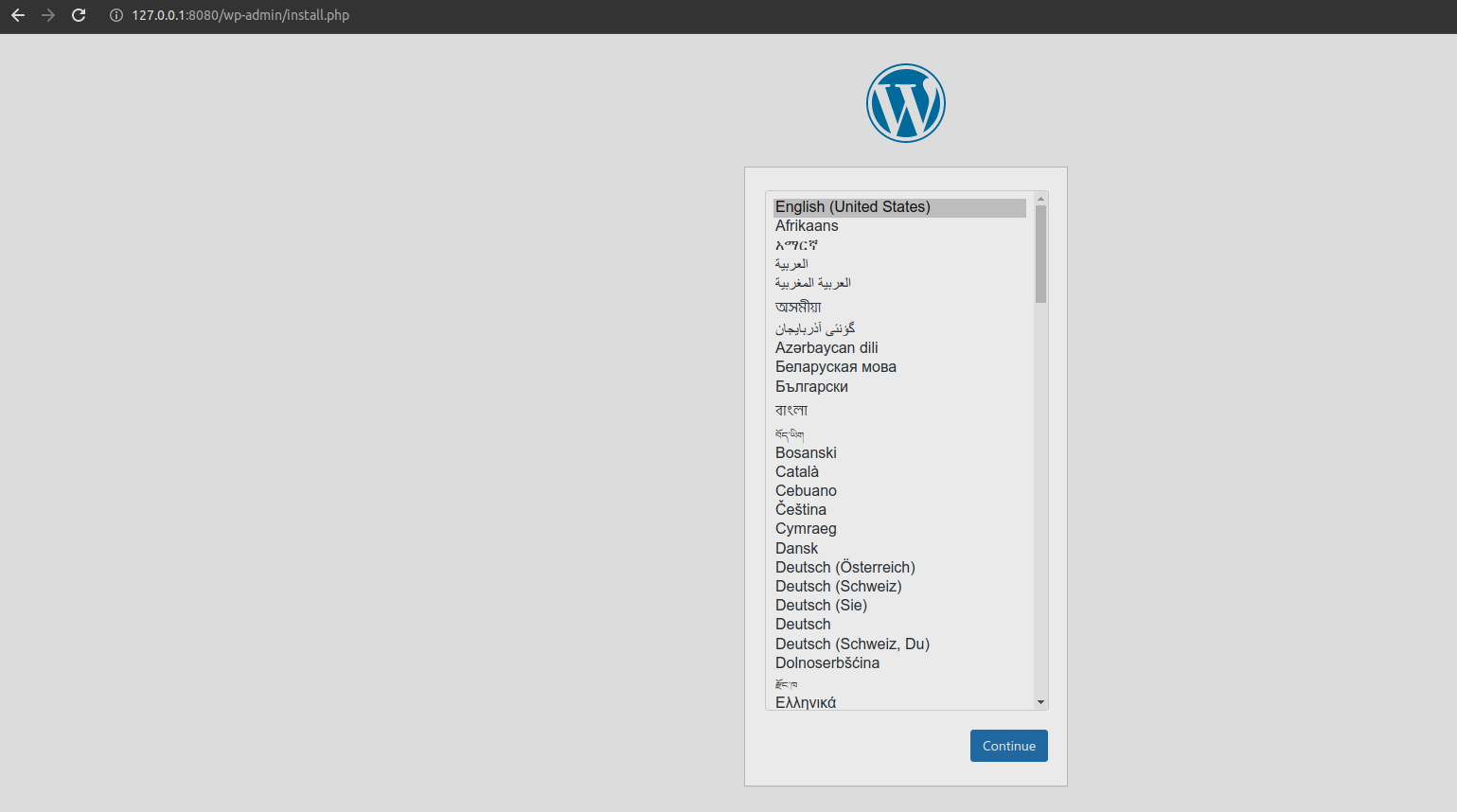
也可以在 Kubernetes 里使用命令 kubectl logs 查看 WordPress、MariaDB 等 Pod 的运行日志,来验证它们是否已经正确地响应了请求:
使用 Dashboard 管理 Kubernetes
启动Dashboard
1 | minikube dashboard |
它会自动打开浏览器界面,显示出当前 Kubernetes 集群里的工作负载:
点击任意一个 Pod 的名字,就会进入管理界面,可以看到 Pod 的详细信息,而右上角有 4 个很重要的功能,分别可以查看日志、进入 Pod 内部、编辑 Pod 和删除 Pod,相当于执行 logs、exec、edit、delete 命令: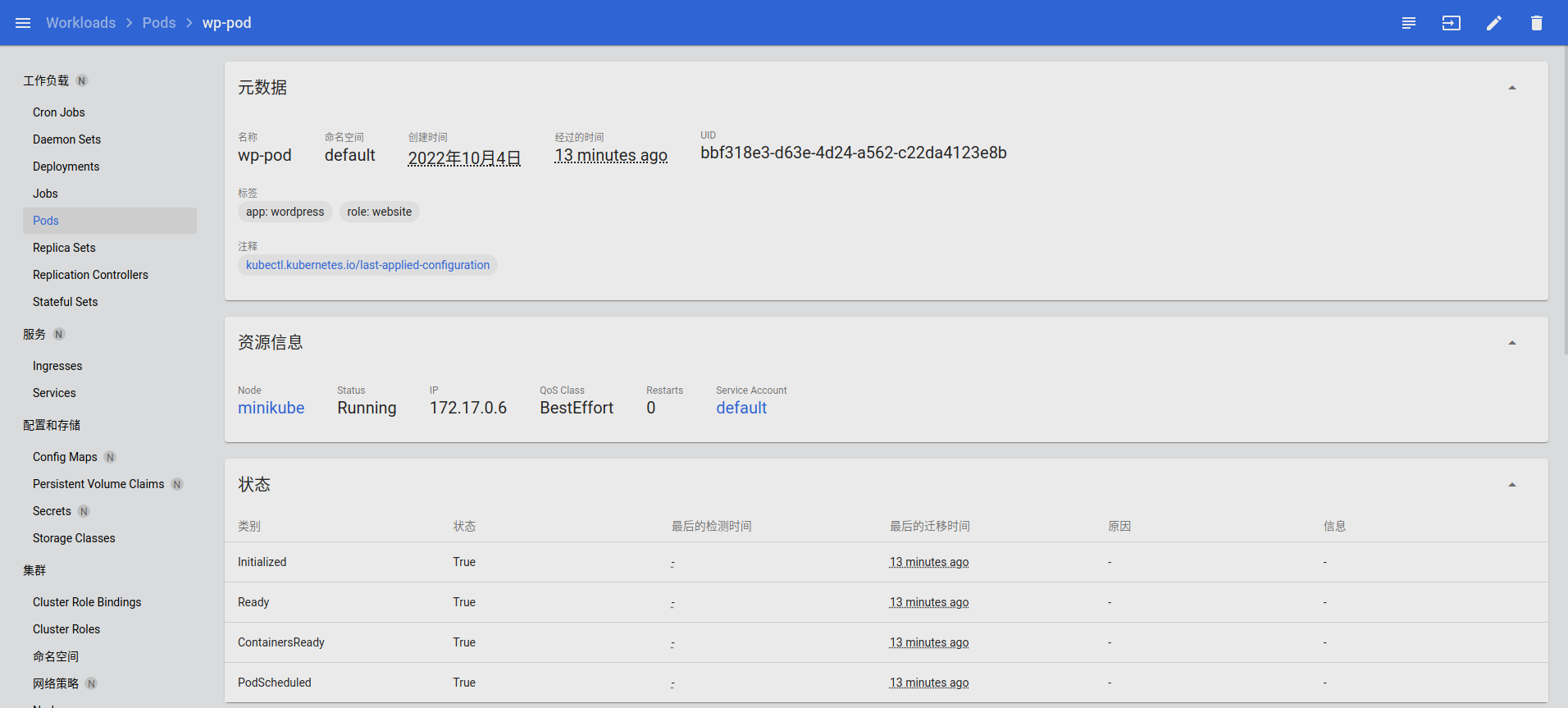
ConfigMap/Secret 等对象也可以在这里任意查看或编辑: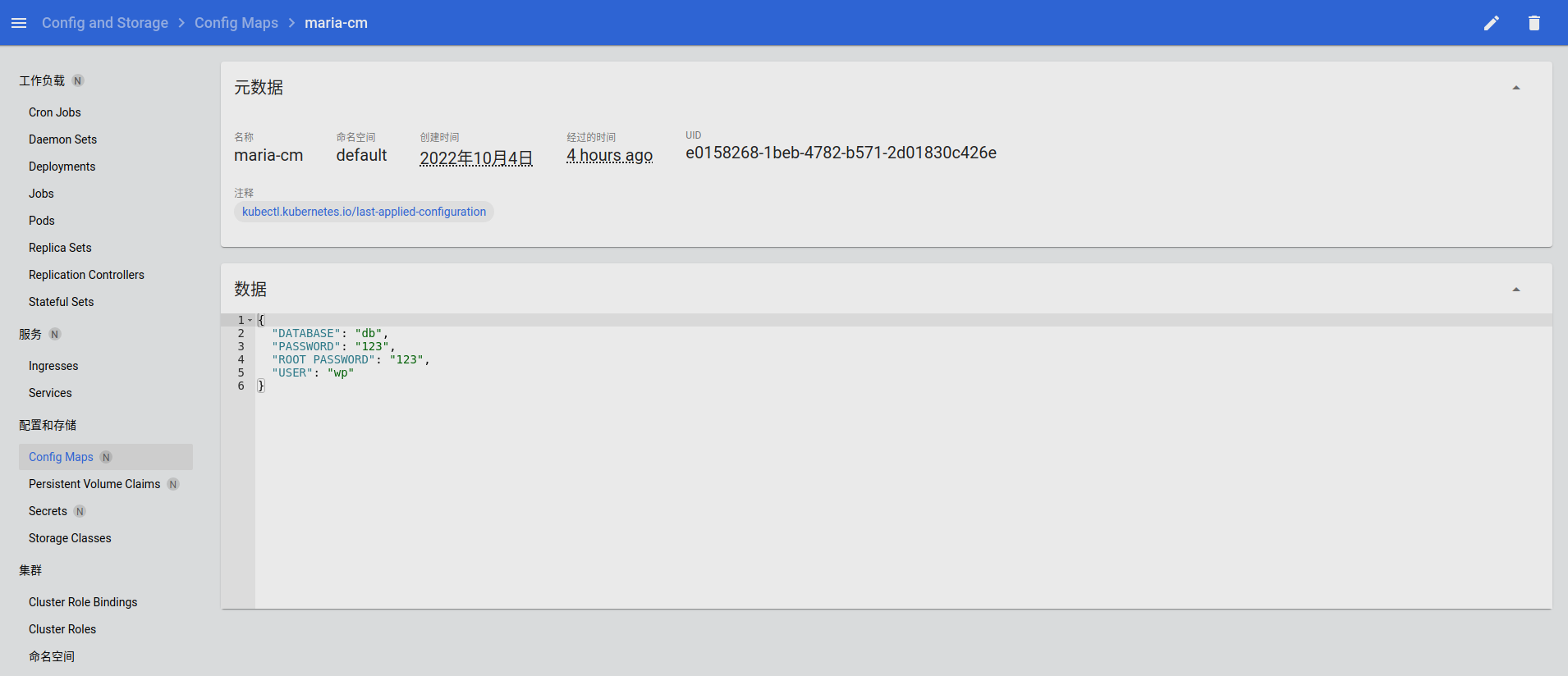
答疑
Kubernetes 系统和 Docker 系统的区别在哪里?
关键就在对应用的封装和网络环境这两点上。
现在 WordPress、MariaDB 这两个应用被封装成了 Pod(由于它们都是在线业务,所以 Job/CronJob 在这里派不上用场),运行所需的环境变量也都被改写成 ConfigMap,统一用“声明式”来管理,比起 Shell 脚本更容易阅读和版本化管理。
另外,Kubernetes 集群在内部维护了一个自己的专用网络,这个网络和外界隔离,要用特殊的“端口转发”方式来传递数据,还需要在集群之外用 Nginx 反向代理这个地址,这样才能实现内外沟通。
总结
容器技术开启了云原生的大潮,但成熟的容器技术,到生产环境的应用部署的时候,却显得“步履维艰”。因为容器只是针对单个进程的隔离和封装,而实际的应用场景却是要求许多的应用进程互相协同工作,其中的各种关系和需求非常复杂,在容器这个技术层次很难掌控。
为了解决这个问题,容器编排(Container Orchestration)就出现了,它可以说是以前的运维工作在云原生世界的落地实践,本质上还是在集群里调度管理应用程序,只不过管理的主体由人变成了计算机,管理的目标由原生进程变成了容器和镜像。
而现在,容器编排领域的王者就是——Kubernetes。
Kubernetes 源自 Borg 系统,它凝聚了 Google 的内部经验和 CNCF 的社区智慧,所以战胜了竞争对手 Apache Mesos 和 Docker Swarm,成为了容器编排领域的事实标准,也成为了云原生时代的基础操作系统,学习云原生就必须要掌握 Kubernetes。
Kubernetes 的 Master/Node 架构是它具有自动化运维能力的关键: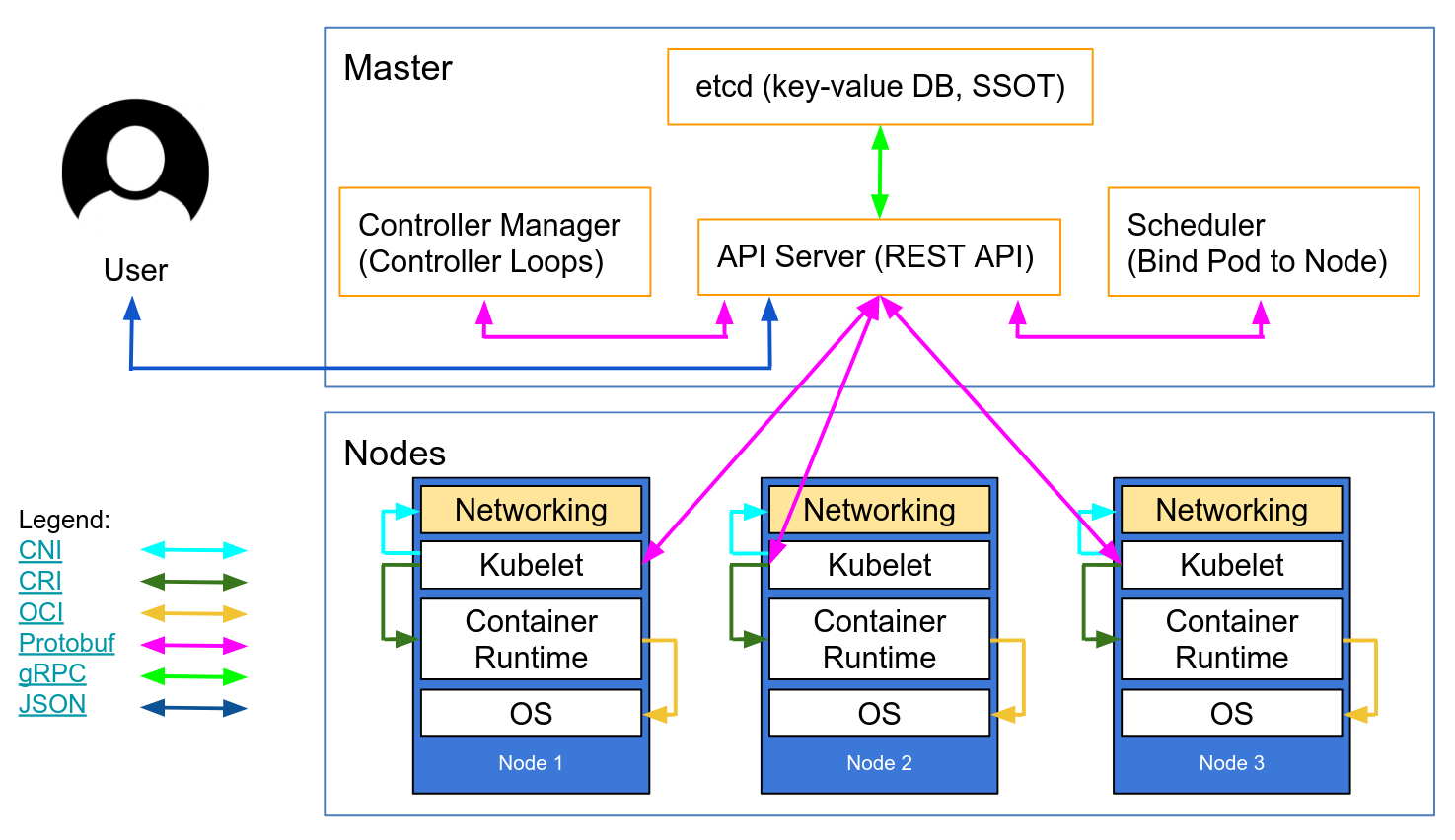
Kubernetes 把集群里的计算资源定义为节点(Node),其中又划分成控制面和数据面两类。
- 控制面是 Master 节点,负责管理集群和运维监控应用,里面的核心组件是 apiserver、etcd、scheduler、controller-manager。
- 数据面是 Worker 节点,受 Master 节点的管控,里面的核心组件是 kubelet、kube-proxy、container-runtime。
此外,Kubernetes 还支持插件机制,能够灵活扩展各项功能,常用的插件有 DNS 和 Dashboard。
为了更好地管理集群和业务应用,Kubernetes 从现实世界中抽象出了许多概念,称为“API 对象”,描述这些对象就需要使用 YAML 语言。
YAML 是 JSON 的超集,但语法更简洁,表现能力更强,更重要的是它以“声明式”来表述对象的状态,不涉及具体的操作细节,这样 Kubernetes 就能够依靠存储在 etcd 里集群的状态信息,不断地“调控”对象,直至实际状态与期望状态相同,这个过程就是 Kubernetes 的自动化运维管理。
Kubernetes 里有很多的 API 对象,其中最核心的对象是“Pod”,它捆绑了一组存在密切协作关系的容器,容器之间共享网络和存储,在集群里必须一起调度一起运行。通过 Pod 这个概念,Kubernetes 就简化了对容器的管理工作,其他的所有任务都是通过对 Pod 这个最小单位的再包装来实现的。
除了核心的 Pod 对象,基于“单一职责”和“对象组合”这两个基本原则,又有了 Job/CronJob 和 ConfigMap/Secret:
- Job/CronJob 对应的是离线作业,它们逐层包装了 Pod,添加了作业控制和定时规则
- ConfigMap/Secret 对应的是配置信息,需要以环境变量或者存储卷的形式注入进 Pod,然后进程才能在运行时使用
和 Docker 类似,Kubernetes 也提供一个客户端工具,名字叫“kubectl”,它直接与 Master 节点的 apiserver 通信,把 YAML 文件发送给 RESTful 接口,从而触发 Kubernetes 的对象管理工作流程。
使用 YAML 描述 API 对象也有固定的格式,必须写的“头字段”是“apiVersion”“kind”“metadata”,它们表示对象的版本、种类和名字等元信息。实体对象如 Pod、Job、CronJob 会再有“spec”字段描述对象的期望状态,最基本的就是容器信息,非实体对象如 ConfigMap、Secret 使用的是“data”字段,记录一些静态的字符串信息。