题目
和判断两个链表是否相交类似。
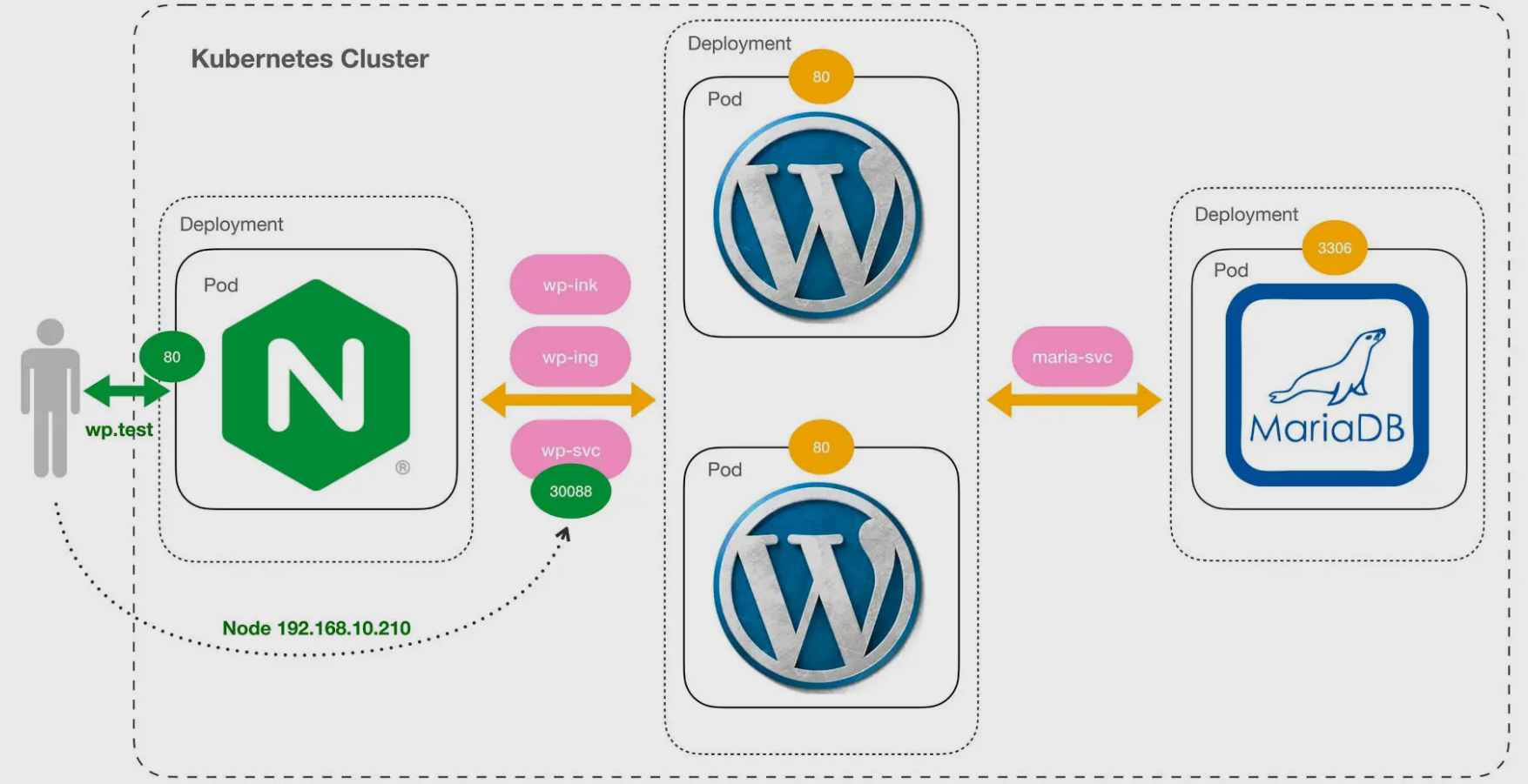
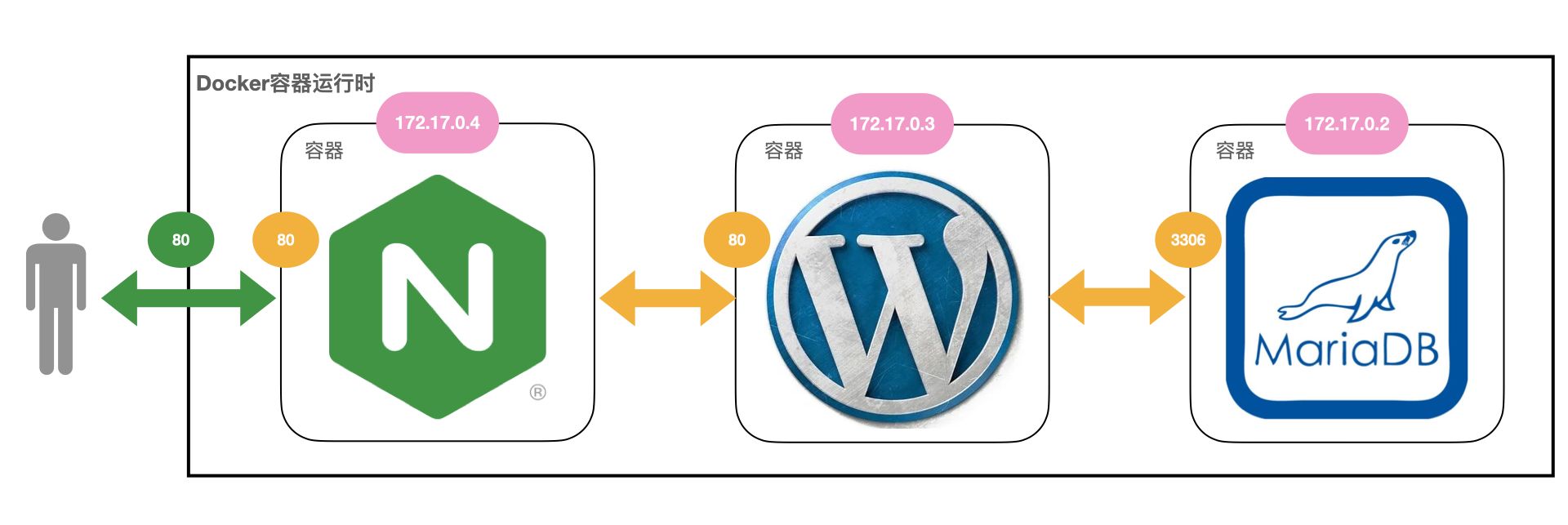
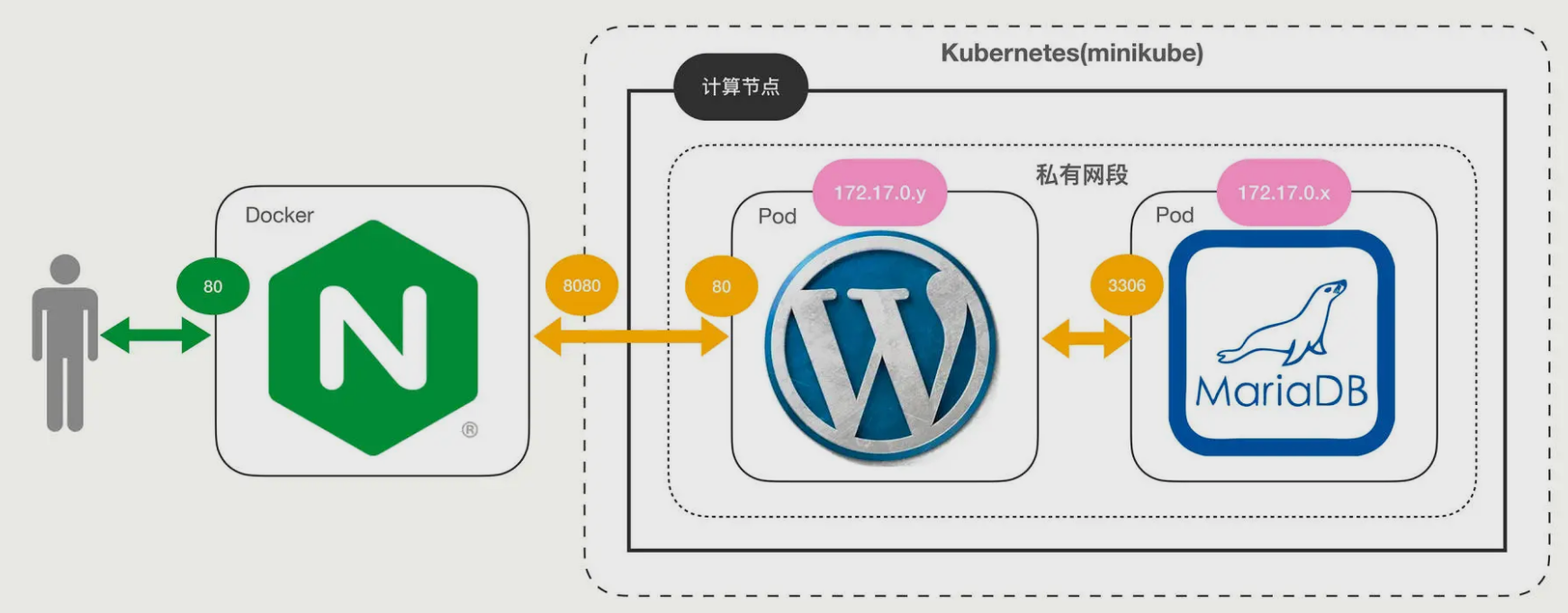
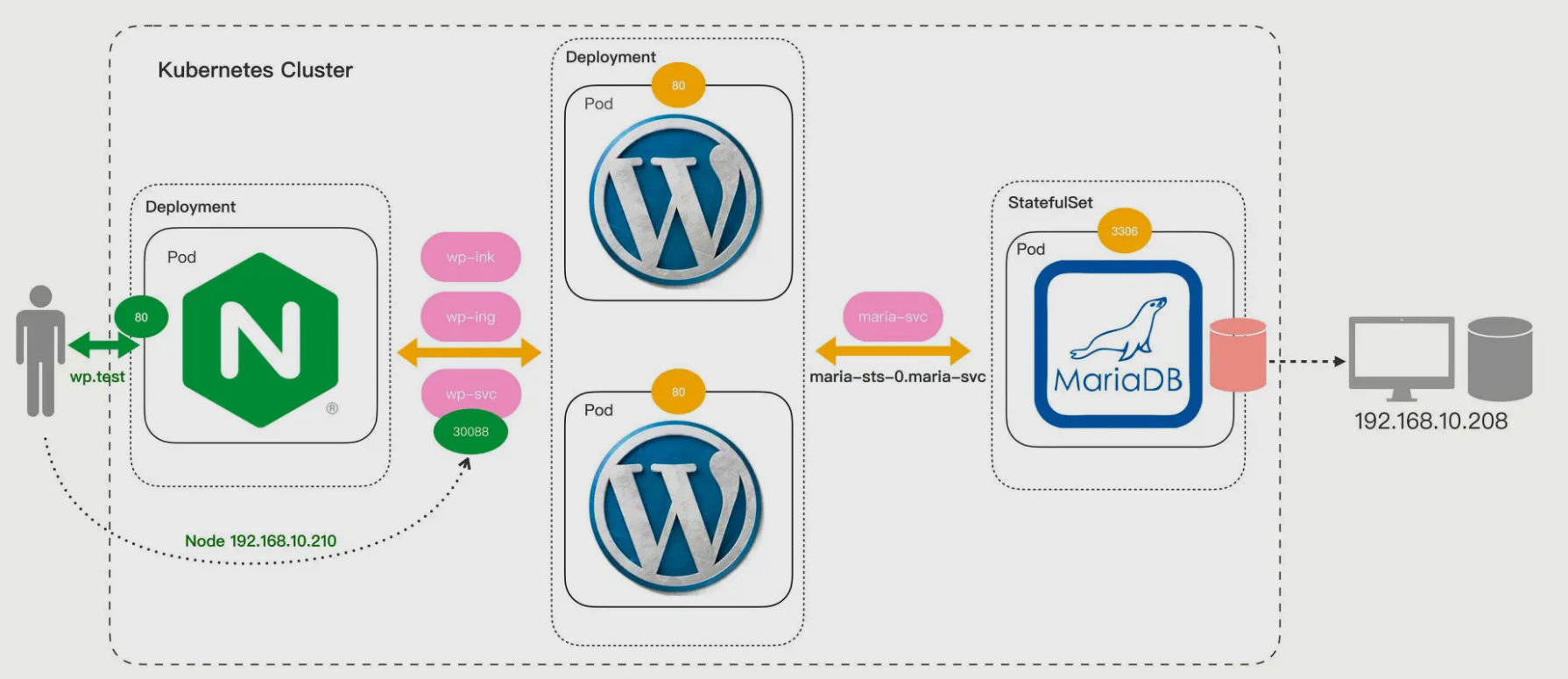
在基于版本2的基础上继续优化 WordPress 网站的部署,其中的关键是让数据库 MariaDB 实现数据持久化。
网站的整体架构图变化不大,前面的 Nginx、WordPress 还是原样,只需要修改 MariaDB:
本文将介绍如何搭建最简单的私有镜像仓库——Docker Registry。
首先,你需要使用 docker pull 命令拉取镜像:
1 | # docker pull registry |
然后,我们需要做一个端口映射,对外暴露端口,这样 Docker Registry 才能提供服务。它的容器内端口是 5000,简单起见,我们在外面也使用同样的 5000 端口,所以运行命令:
1 | # docker run -d -p 5000:5000 registry |
1 | # 更新 |