ClickHouse简介
- ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS);
- 列式数据库更适合于OLAP场景(对于大多数查询而言,处理速度至少提高了100倍);
安装部署
在线
1 | # 更新 |
1 | # 更新 |
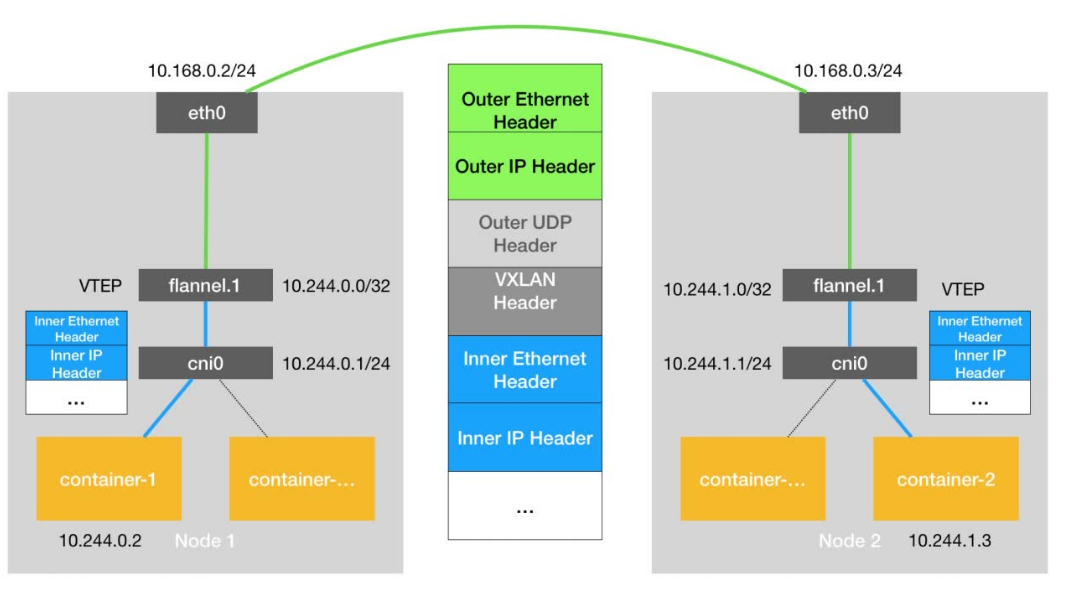
全局的、为了代理不同后端 Service 而设置的负载均衡服务,就是 Kubernetes 里的Ingress 服务。
所以,Ingress 的功能其实很容易理解:所谓 Ingress,就是 Service 的“Service”。
假如我现在有这样一个站点:https://cafe.example.com,其中https://cafe.example.com/coffee对应的是“咖啡点餐系统”,而https://cafe.example.com/tea对应的是茶水点餐系统,这两个系统,分别由名叫coffee和tea两个Deployment来提供服。
那么,我如何能使用 Kubernetes 的 Ingress 来创建一个统一的负载均衡器,从而实现当用户访问不同的域名时,能够访问到不同的 Deployment 呢?
上述功能,在 Kubernetes 里就需要通过 Ingress 对象来描述:
API对象定义:
1 | apiVersion: batch/v1 |
在这个模板中,我们定义了一个Ubuntu镜像的容器,他运行计算π的程序,所以,这是一个计算π的容器。
创建成功后,查看一下这个Job对象:
//TODO:
可以看到,在这个Job对象创建后,它的Pod模板被自动加上了一个controller-uid=<一个随机字符串>这样的Label。从而保证了Job与它所管理的Pod之间的匹配关系。